

An Engineer's Guide to Fine-Tuning LLMs, Part 2: The Execution Playbook
A deep dive into the methods, fine-tuning pipeline, and operational risks of building specialised models.

Introduction: From Strategy to Execution
In Part 1, we established the strategic framework. You now know where fine-tuning fits in the LLM value chain, the green flags that signal it's the right move, and the critical red flags that tell you to walk away. You’ve made the call.
But the decision is only the beginning. The gap between choosing to fine-tune and successfully deploying a specialised, reliable model is where most engineering teams stumble. It's a gap bridged not by hope, but by discipline.
This issue is the playbook for that discipline. We will walk through each critical stage of the fine-tuning loop:
Data Curation: How to build a high-quality dataset that defines your model's new behaviour.
Methods and Trade-offs: How to choose the right tool for the job, from Full SFT to the efficiency of PEFT.
The Core Loop: A deep dive into the mechanics of configuring, running, and evaluating a training job.
Risk Management: A guide to identifying and preventing the common failure modes that can silently break your model.

Welcome to Part 2. Let's get to work.
1. Designing the Fine-Tuning Loop: A Systems View
The biggest myth in fine-tuning is that it's a one-and-done process. That you can build the perfect dataset, push a button, and get a production-ready model on the first try.
The engineering reality is different: successful fine-tuning is a loop.

This loop has five distinct stages:
Define the Task: Get crystal clear on the specific behaviour you are trying to teach. Is it a format, a style, a reasoning pattern, or a classification skill? A vague goal leads to a vague model.
Curate the Dataset: Build a high-quality dataset that is a perfect representation of the target behaviour. This is the specification for your model.
Choose a Method & Train: Select the right technique for your goal and budget (e.g., PEFT vs. Full SFT) and execute the training job.
Evaluate the Result: Rigorously test the model's performance, not just on metrics, but on its qualitative behaviour. Find where it fails.
Refine and Repeat: Analyze the failures, use those insights to improve your dataset or training configuration, and begin the loop again.
This brings us to the most important principle for builders: you must reject the "one-shot tuning fallacy."
Your goal for the first pass is not to build a perfect model. It is to build a Minimum Viable Model (MVM) whose primary function is to fail in interesting and informative ways. Those failures, the edge cases it gets wrong, the formats it breaks, the biases it reveals, are the most valuable signal you have. They are the data you will use to refine your process for the next iteration.
The following sections are a deep dive into each stage of this loop. We'll start with the most critical input, and the foundation of all behaviour: your data.
2. Data Curation: The Foundation of Behaviour
In the fine-tuning loop, no stage has more leverage than data curation. The model, training script, and hyperparameters are important, but the dataset is the foundation upon which everything is built. If your data is flawed, no amount of clever engineering can save the project.
Think of it this way: your dataset is the source code for your model's new behaviour. Every example is a line of code that defines how the model should think, act, and respond. Your job is to write the cleanest, most intentional code possible.
The Anatomy of a "Golden" Example
Before discussing quantity or format, let's define what a single, high-quality data point looks like. A "golden" example isn't just an input and an output; it's a perfect demonstration of the exact behaviour you want to instill.
It contains three parts:
The Instruction (The Task): A clear, unambiguous prompt that defines the task the model should perform.
The Context (The Input, optional): Any additional information the model needs to perform the task, such as a user query or a piece of text to summarize.
The Completion (The Target Behaviour): The ideal response. This is the most important part, it must be a perfect example of the desired tone, format, and reasoning pattern.
Illustrative Scenario: You want to fine-tune a model to be a helpful but firm support agent that politely deflects feature requests that are out of scope.
A golden example would look like this:

This single example teaches the model the desired tone (polite, appreciative), the core task (deflection), and the correct format (a helpful, closing question).
Standard Data Formats
Your dataset must be formatted precisely for the tools you're using. The two most common structures are:
For the OpenAI API: A .jsonl file where each line is a JSON object containing a list of messages. This format models a conversation and requires specifying roles (system, user, assistant).
{"messages": [{"role": "system", "content": "You are a helpful but firm support agent."}, {"role": "user", "content": "Can you add Klingon language support?"}, {"role": "assistant", "content": "That's a creative idea! While we don't currently have plans to add Klingon, I've passed your feedback along to the team."}]}For Open-Source Models (Hugging Face TRL): Typically, a list of dictionaries. The structure can vary, but a common format for instruction-following is a dictionary with keys like instruction, input, and output, often formatted into a single string with special tokens.
[
{
"instruction": "You are a support agent who must politely decline feature requests...",
"input": "User query: 'Will you add interplanetary communication protocols?'",
"output": "That's a fascinating question! While we're focused on terrestrial communication for now..."
}
]The "Quality Over Quantity" Mandate
The most common myth in fine-tuning is that you need a massive dataset. The reality is that 1,000 high-quality, curated examples will outperform 50,000 noisy, inconsistent examples every time.
Fine-tuning is a process of pattern imitation. A small, clean dataset teaches the model a clear, strong pattern to follow. A large, noisy dataset teaches the model a confusing, noisy pattern, resulting in erratic behaviour. Your goal is to create the strongest, cleanest signal possible.
Data Sourcing and Cleaning
Sourcing: High-quality data often comes from existing human-in-the-loop processes, such as support tickets handled by your best agents or documents written by domain experts. Alternatively, you can use a powerful "teacher" model (like GPT-4o) to generate a synthetic dataset, but this requires careful prompting and rigorous quality control.
Cleaning: Before training, your dataset must be cleaned. This is a non-negotiable step.
Remove Duplicates: Identical or near-identical examples don't add value and can bias the model.
Filter for Quality: Remove examples that are unclear, contain errors, or don't strongly represent the target behaviour.
Check for PII: Scrub all personally identifiable information from your dataset to protect user privacy.
Ensure Consistency: The tone, style, and format across all of your examples should be as consistent as possible.
With a high-quality dataset curated and formatted, you have laid the foundation. The next step is to choose the right engine to power the training process.
3. Methods and Trade-offs: Choosing Your Engine
With a high-quality dataset ready, your next critical decision is choosing the right engine for the job. The "best" fine-tuning method doesn't exist; the right choice is a direct function of your goal, budget, and performance needs.
This section is your guide to making that trade-off, breaking down the core training methods and advanced techniques for production efficiency.
Core Training Methods
1. Full Fine-Tuning (SFT)
What it is: The most comprehensive approach, where you update every weight in a pretrained model using your labelled dataset.
Where it shines: When you need to teach the model a new, complex skill from scratch (e.g., mastering a highly specialised grammar) and have a massive, high-quality dataset to maximise performance.
The Trade-off: It is prohibitively expensive and carries a high risk of overfitting on smaller datasets and catastrophic forgetting of the model's general capabilities. While techniques like regularisation can help mitigate overfitting, they add to the complexity.
2. Parameter-Efficient Fine-Tuning (PEFT)
What it is: A family of techniques, like LoRA and QLoRA, that freezes the vast majority of the model's weights and only trains a very small number of new, "adapter" parameters.
Where it shines: This is the default choice for most use cases, especially for adapting a model's style, format, or domain-specific knowledge. It achieves performance highly comparable to a full fine-tune on these tasks at a fraction of the cost.
The Trade-off: While very powerful, PEFT has limitations when teaching capabilities that are very distant from the base model's knowledge. Its effectiveness on entirely new skills depends on the adapter configuration and task complexity.
3. Preference Tuning
What it is: A method for aligning a model to subjective human preferences (like helpfulness or brand voice) using
chosenvs.rejectedresponse pairs. The two main approaches are:RLHF (Reinforcement Learning from Human Feedback): A complex process that first trains a separate "reward model" on human preferences, then uses RL to tune the LLM.
DPO (Direct Preference Optimization): A more modern and stable method that uses a direct loss function on preference pairs to implicitly optimize the same objective as RLHF, avoiding the complexity of training a separate reward model.
Where it shines: Excellent for subjective qualities like tone, personality, and safety, where there isn't a single correct output. DPO is now the standard due to its simplicity and stability.
The Trade-off: It requires expensive human-labelled preference data and does not guarantee factual correctness; it only optimises for being preferred.

Advanced Techniques for Efficiency and Scale
These are powerful techniques you can use to make your model viable for production.
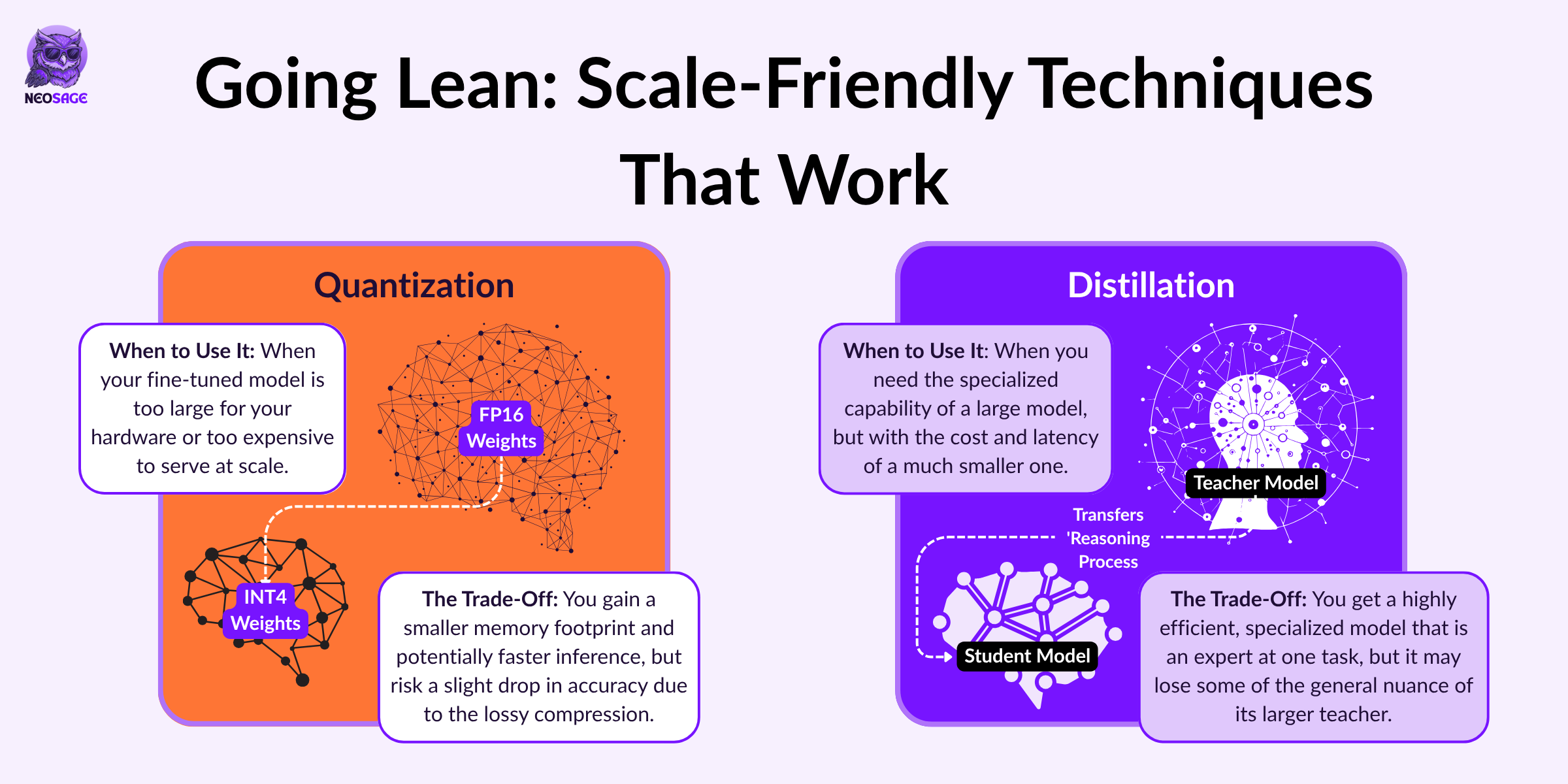
1. Quantization
What it is: A compression technique that reduces the numerical precision of the model's weights (e.g., from 16-bit to 4-bit). While it's often applied post-training, more advanced methods like Quantization-Aware Training (QAT) apply it during the fine-tuning process for more robust performance.
Why you use it: To shrink a model's memory footprint so it can be served on smaller, cheaper GPUs.
The Trade-off: It is a "lossy" compression, which can degrade model performance. Significant inference speed-ups are also not guaranteed and depend on your specific hardware supporting low-bit operations.
2. Distillation
What it is: A training technique where a smaller "student" model is trained to mimic the outputs of a larger "teacher" model. This is often done by training the student on the teacher's output probabilities (logits) or intermediate representations, effectively transferring the teacher's "reasoning process."
Why you use it: To get the performance of a state-of-the-art "teacher" model (like GPT-4o) in a small, fast, and cheap "student" model that can be served at scale.
The Trade-off: You transfer a specific skill with high efficiency, but the student may lose some of the teacher's general nuance and will likely not outperform it on out-of-domain tasks.
Choosing your engine is a crucial architectural decision. Whether you opt for the raw power of Full SFT or the surgical efficiency of PEFT, you are making a deliberate trade-off between capability and cost.
With your method selected, it's time to enter the core of the playbook: the iterative loop of training and evaluation.
4. The Training and Evaluation Loop
You have your dataset, and you've chosen your method. Now you enter the engine room of the playbook: the iterative loop of training a model and rigorously evaluating its behaviour. This is where the real work of shaping your model happens.
The Training Run: Configuration and Monitoring
A successful training run is not about luck; it's about a correct and thoughtful configuration. While there are dozens of parameters you can set, a few are critical for success.
Key Hyperparameters to Configure:
learning_rate: This is the most sensitive dial. For fine-tuning, you need a very low learning rate (e.g.,
5e-5to2e-5) to stably adapt the model. For even more stability, this is often paired with a learning rate scheduler (like cosine decay) that gradually decreases the rate during training.num_train_epochs: The number of times the model will see your entire training dataset. For large datasets, this is often just 1-3 to prevent overfitting.
per_device_train_batch_size: The number of examples processed per GPU at once. A larger batch size can lead to more stable and faster convergence, but it must be tuned to fit your GPU memory constraints.
Monitoring the Run: Interpreting the Loss Curve
As the model trains, you must monitor its train_loss (the error on the data it's actively learning from) and your eval_loss or validation_loss (the error on a held-out dataset to check for generalisation). This held-out validation dataset is critical—it must be high-quality and representative of your production data to give you an honest signal.
The shape of these curves tells you what's happening. A healthy run shows both curves decreasing. If your train_loss continues to fall while your validation_loss stagnates or rises, your model is overfitting. This is a clear signal to stop training to save the best-performing checkpoint.
The Evaluation Phase: Did It Actually Work?
Here is a critical truth of fine-tuning: a low validation loss does not mean your model is good. It only means your model got good at predicting the next token in your specific validation set. It says nothing about its real-world behaviour, safety, or reliability.
A professional evaluation strategy is a portfolio of different tests, always benchmarked against the original base model's performance to clearly measure improvement and detect regressions.
A Modern Evaluation Toolkit
1. Quantitative Metrics (for Objective Tasks)
For tasks with a clear right or wrong answer, you should use automated, quantitative metrics.
Use Case: Classification tasks, where you can measure accuracy, precision, recall, and F1-score.
Use Case: Structured data generation. If you're fine-tuning a model to output JSON, your most important metric is simply: "Is the output 100% parsable?" You can programmatically validate this against your required schema.
2. Qualitative Human Review (for Subjective Tasks)
For tasks involving style, tone, or nuanced instructions, human evaluation is non-negotiable. Automated metrics cannot tell you if a response "feels" right.
What to look for: Does the model consistently adopt the desired persona? Is it genuinely helpful? Has it developed any new, undesirable habits?
Best Practice: As you discover new failure modes through human review, feed them back into your evaluation set. A static evaluation set becomes stale over time and allows for regressions on problems you thought you had solved.
3. LLM-as-a-Judge (for Scalable Qualitative Evals)
This is a powerful, modern technique that uses a state-of-the-art model (like GPT-4o or Claude 4 Opus) as a scalable proxy for human evaluators.
How it works: You present the "judge" LLM with the input prompt, your model's generated response, and a detailed rubric. The judge then scores the response based on the rubric's criteria.
Pro Tip: Use a hybrid approach for efficiency. Screen thousands of outputs with a cheap LLM-as-a-Judge, and escalate only the difficult or borderline cases to more expensive human reviewers.
Key Pitfalls: This method is powerful but has known biases:
Verbosity Bias: Tends to prefer longer, more detailed responses, even if they aren't better.
Positional Bias: Can favour the first answer it sees in a side-by-side comparison.
Self-Enhancement Bias: Often gives higher scores to outputs from its own model family (e.g., GPT-4 judging GPT-4).
4. Behavioural Regression Testing
This is your model's "unit test" suite. Before you even start fine-tuning, you should create a fixed set of a few dozen hand-crafted prompts that test for critical, must-have behaviours.
What it tests for:
Safety: Does the model still refuse to answer harmful questions?
Regressions: Has the model "forgotten" how to do a simple task that it could do before?
Edge Cases: Does it correctly handle the specific edge cases you care most about? Run this test suite after every fine-tuning run to ensure you haven't introduced a new problem while fixing another.
The insights from this rigorous evaluation are not the end of the process. They are the input for the next iteration of the loop, feeding back into your data curation and allowing you to systematically improve the model's behaviour.

5. Risk Management: Safety and Failure Modes
Fine-tuning gives you the power to specialise a model, but it also gives you the power to break it in subtle and dangerous ways. The most critical risk is that the process of teaching a model a new skill can override its carefully constructed, general-purpose safety alignment.
Understanding these failure modes is not optional; it's a core competency of responsible model development.
The Primary Risk: Safety Alignment Collapse
State-of-the-art base models have undergone extensive safety tuning on millions of examples to make them refuse harmful requests. When you fine-tune a model, even on a seemingly benign dataset of just a few thousand examples, you create a distributional shift. This new data can "drown out" the original safety training, creating new adversarial vulnerabilities or "jailbreaks."
This safety collapse is particularly dangerous because the risk can be high not only when your data is very different from the base model's training, but also when its distribution is too similar to the safety-tuning data, which can confuse the model into overriding its refusal logic.
Illustrative Scenario: A team fine-tunes a model to be a "witty, sarcastic chatbot" for a gaming community. The training data contains no explicitly harmful content. However, when users in production start interacting with borderline-toxic language, the model now responds with equally toxic sarcasm instead of the firm refusal it was originally trained for. The new "persona" has overwritten its safety layer.
A Checklist of Technical Failure Modes
Beyond safety alignment, several other technical failures can emerge during the fine-tuning process.
1. Catastrophic Forgetting
The Problem: The model becomes highly specialised on your tuning data but loses general capabilities it previously possessed, such as world knowledge, multilingual fluency, or even the ability to perform simple reasoning. This happens when the tuning data is too narrow and overwrites the model's foundational weights.
How to Prevent It:
Use PEFT: This is the best defence. Since methods like LoRA leave the base model weights frozen, they inherently protect against catastrophic forgetting.
Use Mixed Datasets: If using a full fine-tune, augment your specialised dataset with a small percentage (5-10%) of diverse, general-purpose data to keep the original capabilities "active."
Run Regression Evals: Test the tuned model against broad academic benchmarks (e.g., MMLU) to programmatically quantify any drop in general reasoning.
2. Overfitting and Mode Collapse
The Problem: The model learns the style of your training examples so perfectly that it loses all creativity and diversity in its responses. This "mode collapse" leads to generic, repetitive outputs, making the model feel flat and robotic.
How to Prevent It:
Ensure Dataset Diversity: For creative tasks, include multiple valid and varied completions for the same input prompt.
Tune for Fewer Epochs: Overfitting is often a sign of training for too long. For many tasks, 1-2 epochs are sufficient.
Monitor Output Diversity: During evaluation, track metrics like n-gram diversity to programmatically detect a drop in creativity.
3. Bias Amplification
The Problem: Fine-tuning is a powerful amplifier. Any social or demographic biases present in your training data—even subtle ones—will be learned and often exaggerated by the fine-tuned model, leading to unfair or inequitable behaviour.
How to Prevent It:
Pre-Training Data Audits: Before you begin, rigorously audit your dataset for representation skews and potential sources of social bias.
Safeguard Synthetic Data: If using an LLM to generate synthetic data, rigorously audit those outputs for biases inherited from the generator model before using them for fine-tuning.
Slice-Based Evaluations: Do not rely on aggregate metrics. You must evaluate your model's performance on different "slices" of data (e.g., grouped by demographic attributes) to detect and measure where its behaviour is inequitable.
A professional approach to fine-tuning requires defence-in-depth. This includes not just reactive testing but also proactive safety measures, such as gradient filtering to prevent the model from learning from harmful data and exploring continuous alignment techniques to ensure safety is maintained throughout the tuning process.

Conclusion
Across this two-part guide, we’ve systematically dismantled the "black box" of fine-tuning and replaced it with an engineering playbook. You started with the strategy of "when" and "why," and have now walked through the execution of "how."
Here is the focused intuition you've built:
You know that fine-tuning is about changing a model’s core behaviour, not just its knowledge—a surgical tool you reach for only when prompting and RAG are no longer enough.
You have a clear decision-making framework: a set of green flags that signal when to commit (like enforcing structure or mastering a complex task) and the critical red flags that tell you to stop (like insufficient data or the need for immediate control).
You see the process not as a single event, but as an iterative engineering loop: a disciplined cycle of curating data, training, and rigorously evaluating for what actually matters.
You can navigate the methods and trade-offs, choosing between the raw power of Full SFT, the efficiency of PEFT, and the performance-at-scale of distillation to match your specific constraints.
And you know the risks, with a clear understanding of how to mitigate common failures like catastrophic forgetting, bias amplification, and the degradation of safety alignment.
But let’s be clear:
Fine-tuning isn't a checkbox.
It's a surgical override on model behaviour
And every override comes with a responsibility.
At NeoSage, we don’t just teach tools. We teach how to think with them.
And as Nocto would whisper from the shadows of your prompt window

“Steer with context. Train with care. And never change the weights unless you’ve earned the right.”
Your intuition is now tuned.
Hi, just wanted to make a request — could you create a post explaining how we moved from full fine-tuning to using adapters, and then to PEFT for fine-tuning? I think this progression is crucial for anyone who really wants to understand fine-tuning in depth. And not to forget — this Part 2 is just as good as Part 1
Kudos on the informative article Shivani ! How do you manage to overcome the real-world issues such as
1. model metrics not meeting the defined specifications
2. messy inputs in production for eg PDF's with unclear figures as input for a doc processing or ocr usecase