

How GPTs Are Born: Internet Feeding, Token by Token
Inside the system that turned web text into compressed intelligence—how GPTs learn, predict, and sometimes hallucinate.

Introduction
LLMs are everywhere—we use them, we beg them for answers, and we curse them when they mess up.
They feel almost magical—solving Olympiad-level math, writing Ph.d.-grade papers—and yet, they can’t always tell you which number is bigger: 9.11 or 9.9.
That kind of split personality can be maddening.
So how do you actually build with these systems? What makes them brilliant in some tasks, and bafflingly bad in others?
The answers aren't mystical. They come from understanding what an LLM really is—and what goes into creating the GPTs of the world.
Once you get that, you’ll start seeing patterns.
You’ll know why they fail when they do. You’ll start anticipating their quirks. And more importantly, you’ll begin to develop the kind of mental models that let you wield LLMs effectively—in daily use, and in the products you build.
What Is an LLM, Really?
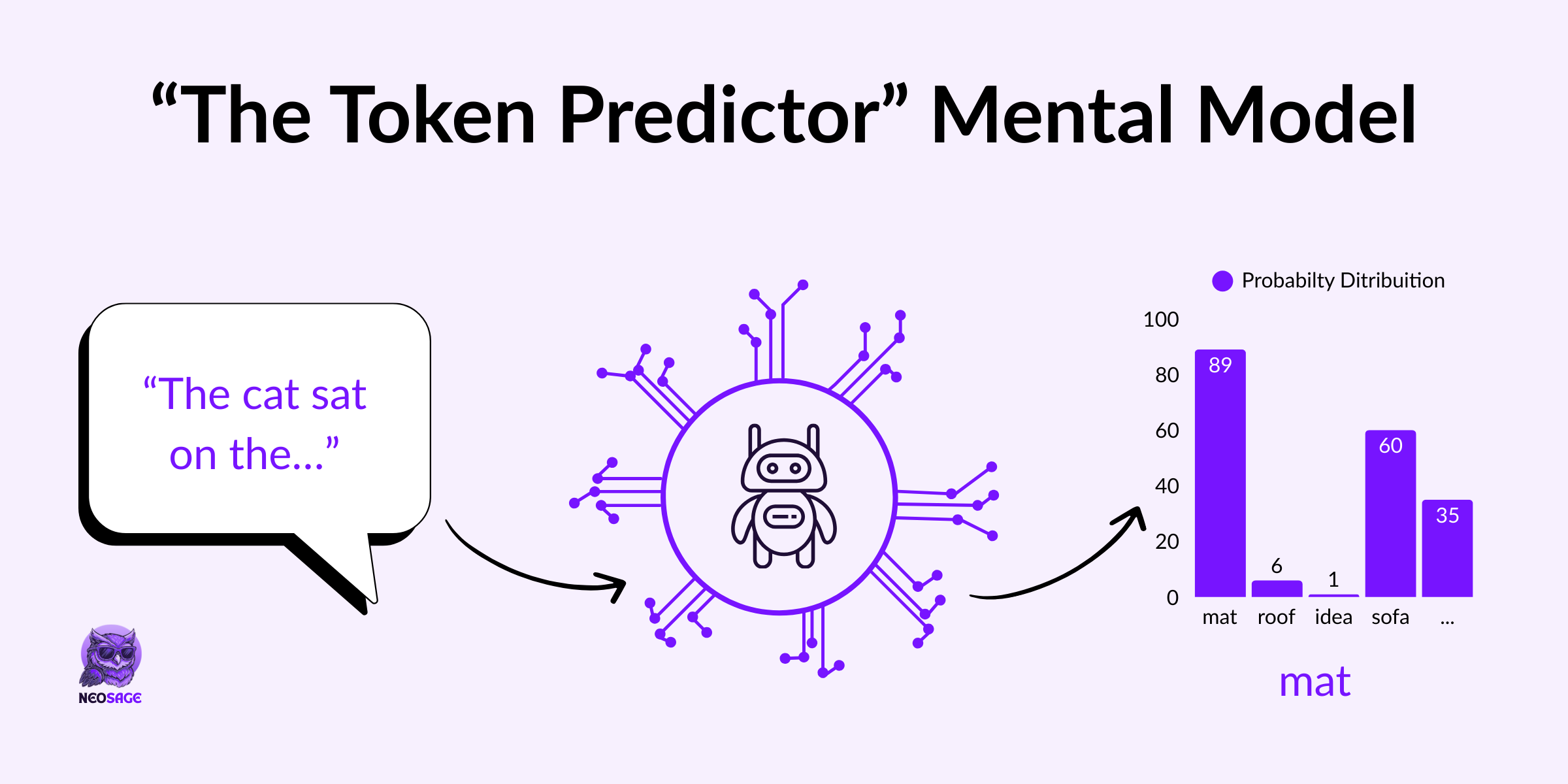
At its core, a Large Language Model is just a next-token prediction machine.
That’s it. It takes a sequence of tokens and guesses, statistically, what comes next.
But don’t let that simplicity fool you.
When this prediction task is scaled up—across trillions of tokens—the model starts doing more than just stringing words together. It builds internal representations of language, concepts, and structure.
It doesn’t “understand” the world like we do.
But it does learn to encode ideas like “cat,” “startup,” or even “grief” in high-dimensional space because it has seen them, again and again, in wildly diverse contexts.
It’s not conscious. It’s not sentient. (Yet ;)
But it has learned a compressed, lossy version of how humans express meaning—and it uses that to autocomplete your sentence.
One token at a time.
Note to the reader:
This issue's goal is to help you develop a strong intuition about how LLMs are created—the way we know and use them today.
There’s a ton of nuance under the hood, but much of it has been intentionally abstracted to keep the concepts accessible and the mental models sharp. Think of this as your map, not the full terrain.
How Is a GPT Born?
If an LLM is a next-token prediction machine, then how does something like GPT-4 come to life?
It all starts with one goal:
Turn the entire internet into numbers—and teach a giant neural network to guess what comes next.
This process happens in three major phases:
Pretraining — Build the brain
Supervised Fine-Tuning (SFT) — Teach it to be helpful
Reinforcement Learning (RL + RLHF) — Let it discover better ways to reason and respond
Let’s break these down, starting with the most compute-heavy phase of all: pretraining.
Pretraining
Turning the Internet Into Model Food
Before your GPT model can chat, code, or give questionable dating advice, it goes through pretraining.
This is where it learns language, patterns, and structure—all by observing the internet.
To make that happen, you first need to collect, clean, and structure the data at massive scale.
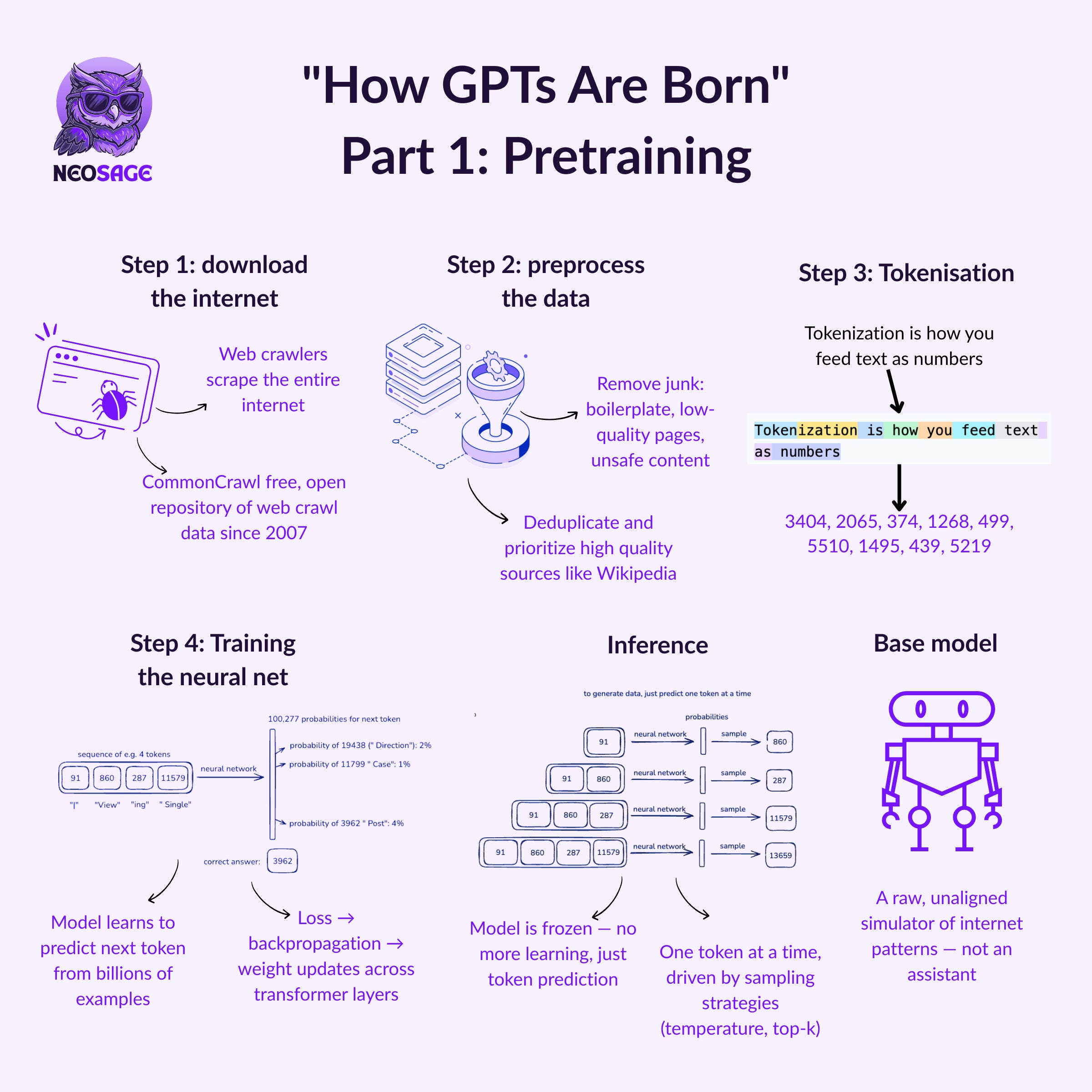
Step 1: Crawl the Web
To train a language model, you first need text—a lot of it.
Big labs like OpenAI, Anthropic, and Google usually operate their own web crawlers: automated bots that surf the internet, follow links, and download publicly available pages.
But there's also Common Crawl, a massive open-source project that has indexed over 250 billion web pages since 2007 and adds billions more every month.
Whether labs use Common Crawl, their own crawlers, or both, the output is more or less the same:
A giant pile of raw web data.
Unfiltered. Untagged. Repetitive. Messy.
Before it can be used to train anything, this data needs to be cleaned, deduplicated, and structured into something the model can actually learn from.
Step 2: Clean the Chaos

Raw web data isn’t ready for training out of the box.
It needs to be heavily preprocessed before a model can learn from it.
Here’s what that cleaning typically involves:
URL filtering – Remove spammy, unsafe, or blacklisted domains (blocklists + heuristics)
Text extraction – Strip away HTML, scripts, boilerplate, and navigation junk
Language filtering – Detect and keep mostly-English pages (e.g. ≥65% English by content)
Deduplication – Use hashing techniques like MinHash to remove near-identical documents
PII removal – Automatically detect and scrub emails, addresses, and personal details
Content ranking – Weight sources like Wikipedia, books, and code repositories higher in the mix
Only after this multi-step scrubbing does the dataset become usable for training.
A good example? Hugging Face’s FineWeb—built on top of Common Crawl and C4, but curated with multiple filtering passes to create a clean, diverse corpus optimised for LLMs.
Step 3: Tokenization
Turning Text Into Numbers

Neural networks don’t read text like we do.
They work with numbers—vectors, matrices, probabilities.
So before training can begin, all that cleaned-up internet data needs to be tokenized—broken into smaller chunks called tokens, and mapped to unique numerical IDs.
But here’s the challenge:
You can’t just feed the raw characters (too long, too inefficient)
You can’t use whole words either (too many of them, and it's not agnostic to typos or new words)
Tokens hit the sweet spot—subword units that are small enough to be reusable, but large enough to be efficient.
For example, the word education might be split into:
["edu", "ca", "tion"] → [2451, 9123, 7812]
The most common technique? Byte Pair Encoding (BPE)—an algorithm that merges frequently seen letter pairs or subwords into new tokens to build a vocabulary.
Once tokenized, every document becomes a sequence of integers.
And that’s what the model trains on—a long list of numbers, learning to predict what comes next.
Not the next word.
Not the next sentence.
Just the next token ID.
Step 4: Training the Neural Network
Teaching the Model to Guess the Next Token

Now that we’ve turned the internet into token IDs, it’s time to teach the model how to predict what comes next.
At a high level, you can consider the LLM to be a giant black box—a deep neural network with billions (or hundreds of billions) of parameters.
Its job?
Take in a sequence of tokens and predict how likely each possible token in the vocabulary is, to occur next.
Let’s say we feed it the phrase:
“The cat sat on the”
The model processes this context and uses its parameters—spread across dozens (or hundreds) of neural layers—to generate a probability distribution over its entire vocabulary.
It might assign:
“mat” → 0.30
“roof” → 0.40
“idea” → 0.01
…and so on for every token it knows
The token with the highest probability is selected (or sampled from), and that becomes the next output.
That’s the entire game:
Take tokens in → guess the next one → repeat
So, how does it learn?
If the model predicts “roof” but the actual word was “mat,” it calculates a loss (usually cross-entropy), and uses backpropagation to nudge all its weights ever so slightly in the right direction.
This happens over and over—across billions of sequences.
Over time, it learns:
The structure of language
The relationships between concepts
And the common patterns behind how humans express thoughts
The result? A model that looks like it understands language—
when it’s really just getting extremely good at continuing sequences of tokens.
And somehow, from this repetitive statistical game…
emerges a system that can code, explain quantum physics, or write you a haiku.
A Peek Inside the Black Box: Transformers and Self-Attention
The Architecture That Made GPTs Possible
So far, we’ve been treating the model as a black box.
But what’s inside that black box?
It’s built using one of the most important breakthroughs in deep learning: the Transformer architecture, introduced in the 2017 paper “Attention is All You Need.”
What made it revolutionary?
It allowed models to attend to all parts of the input simultaneously, rather than sequentially like older RNNs or LSTMs. This gave them a much stronger sense of context—and made training massively parallelizable.
At the heart of this is a mechanism called self-attention.
Self-Attention: Why It Changed Everything
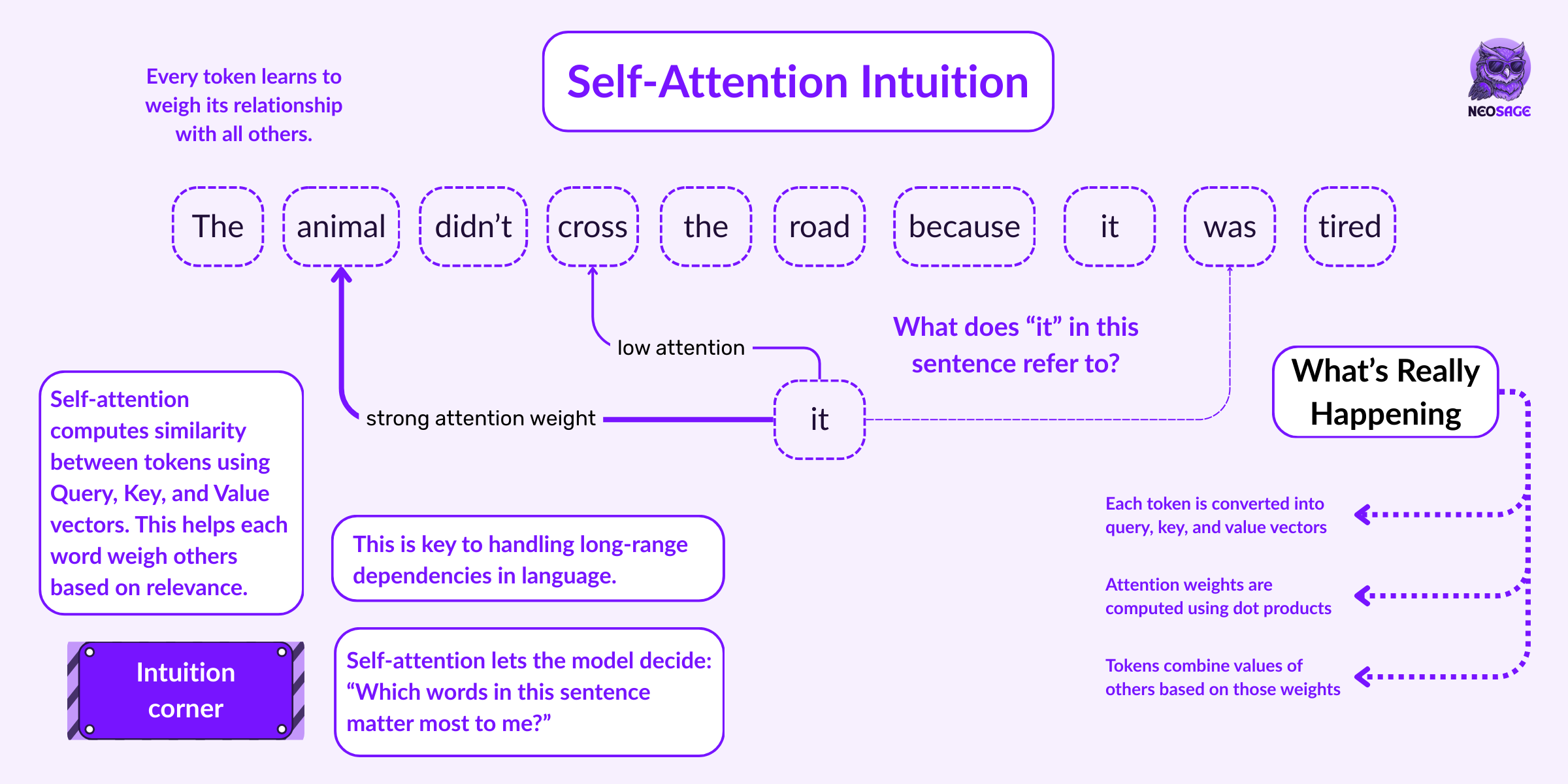
Take the sentence:
“The animal didn’t cross the street because it was tired.”
What does “it” refer to?
Humans instantly link “it” to “the animal.”
But traditional models struggled with this kind of long-range dependency.
Self-attention fixed that.
Self-attention allows every token in the sequence to look at every other token—
and decide how much it should “care” about them when forming its meaning.
So when processing the word “it”, the model can learn to pay more attention to “animal” than to “street.”
Under the hood, this is done by creating three vectors per token:
A query (what am I looking for?)
A key (what do I represent?)
A value (what information do I carry?)
The attention weight is computed using:
Attention = softmax(QKᵀ / √dₖ) · VWhere Q, K, and V are matrices of all query, key, and value vectors in the sequence.
This lets the model build rich representations of tokens in context, across the whole input.
But it doesn’t stop there.
LLMs use Multi-Head Attention—multiple attention mechanisms running in parallel, each learning to focus on different aspects: grammar, logic, meaning, etc.
Each “head” gets a different learned projection of Q, K, and V. The outputs are then concatenated and linearly projected again to form the final attention output.
This allows the model to attend to multiple types of relationships at once.
Why GPT Uses a Decoder-Only Transformer
The original Transformer has two components:
An encoder (to understand full input sequences)
A decoder (to generate sequences, one token at a time)
Models like BERT use the encoder.
But GPTs are decoder-only models, optimized for generation.
Why decoder-only? Because GPTs generate language one token at a time, without looking into the future.
To ensure this, they use masked self-attention, so that each token can only see previous tokens, never the ones ahead.
This is what makes GPTs autoregressive.
They take in a context, and generate the next token, then the next, and so on.
With this setup, the model becomes far more than a simple predictor.
It learns to encode structure, relationships, and meaning—all through attention.
And when you combine this with massive scale?
You get a model that doesn’t just finish your sentence—
Sometimes, it finishes your thought.
Inference: Using the Trained Model
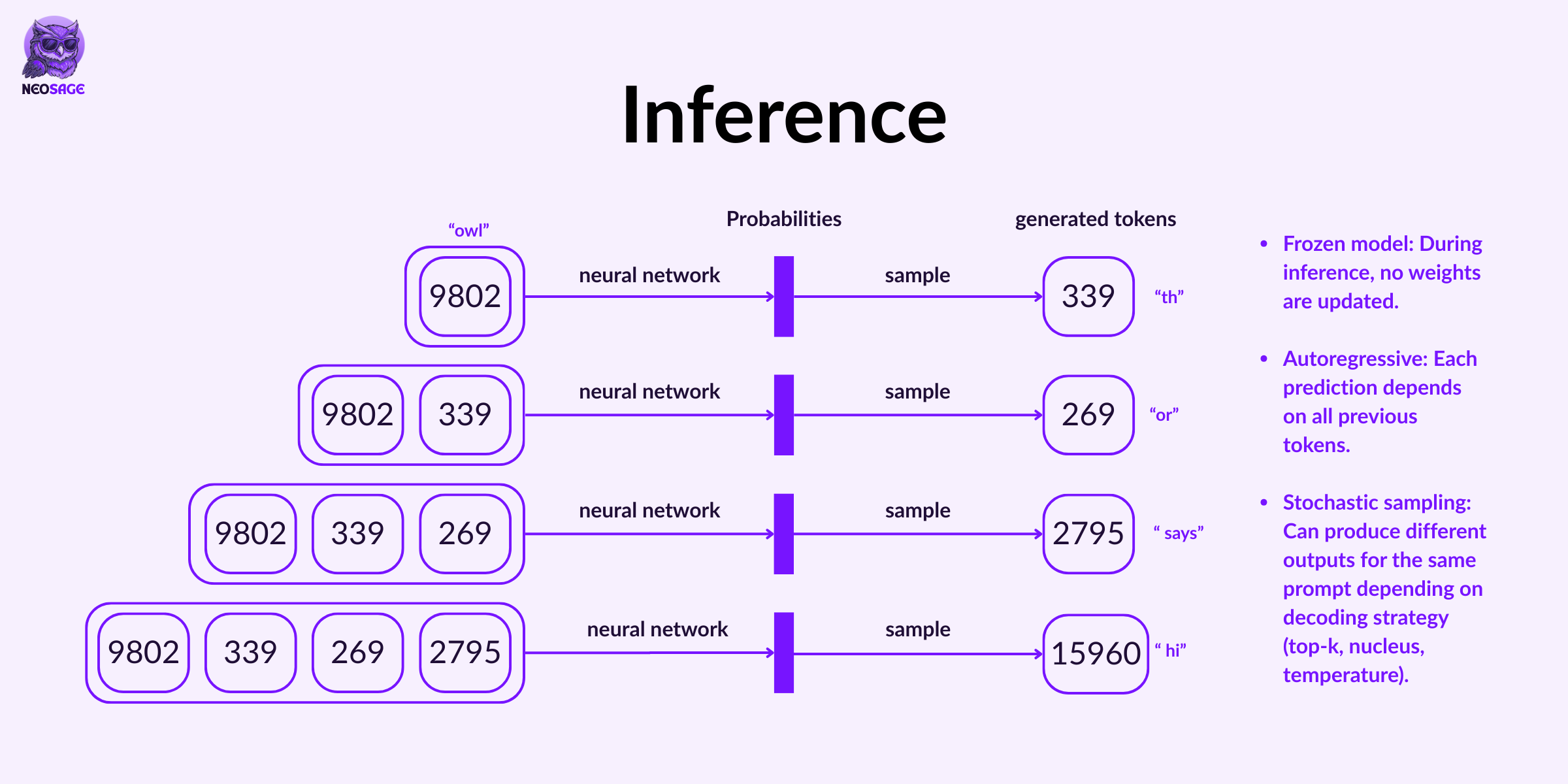
Once training is complete, all the model’s internal weights—the billions of tiny knobs it used to learn patterns—are frozen.
This frozen model is what we now use for inference.
Inference is what happens when you type a prompt into ChatGPT and hit enter.
Behind the scenes, here’s what’s going on:
The model takes your input (already tokenized into numbers), feeds it into its deep neural layers, and computes a probability distribution over all possible next tokens—just like it did during training.
Except now, there’s no ground truth to compare against.
No loss to calculate.
No weights to update.
Inference is the model simply doing what it learned to do:
Predict one token at a time, over and over again, until it decides to stop.
How it chooses the next token depends on sampling strategies, like:
Greedy decoding – always pick the highest probability token (more predictable)
Top-k or nucleus sampling – sample from the top k likely tokens (more diverse or creative)
Temperature – controls randomness; lower = more focused, higher = more exploratory
That’s why the same prompt can sometimes give you different responses.
It’s still just playing autocomplete—
But now it’s fast, frozen, and focused entirely on generation.
Look, Ma, a Base Model!
A Raw, Unaligned Internet Simulator
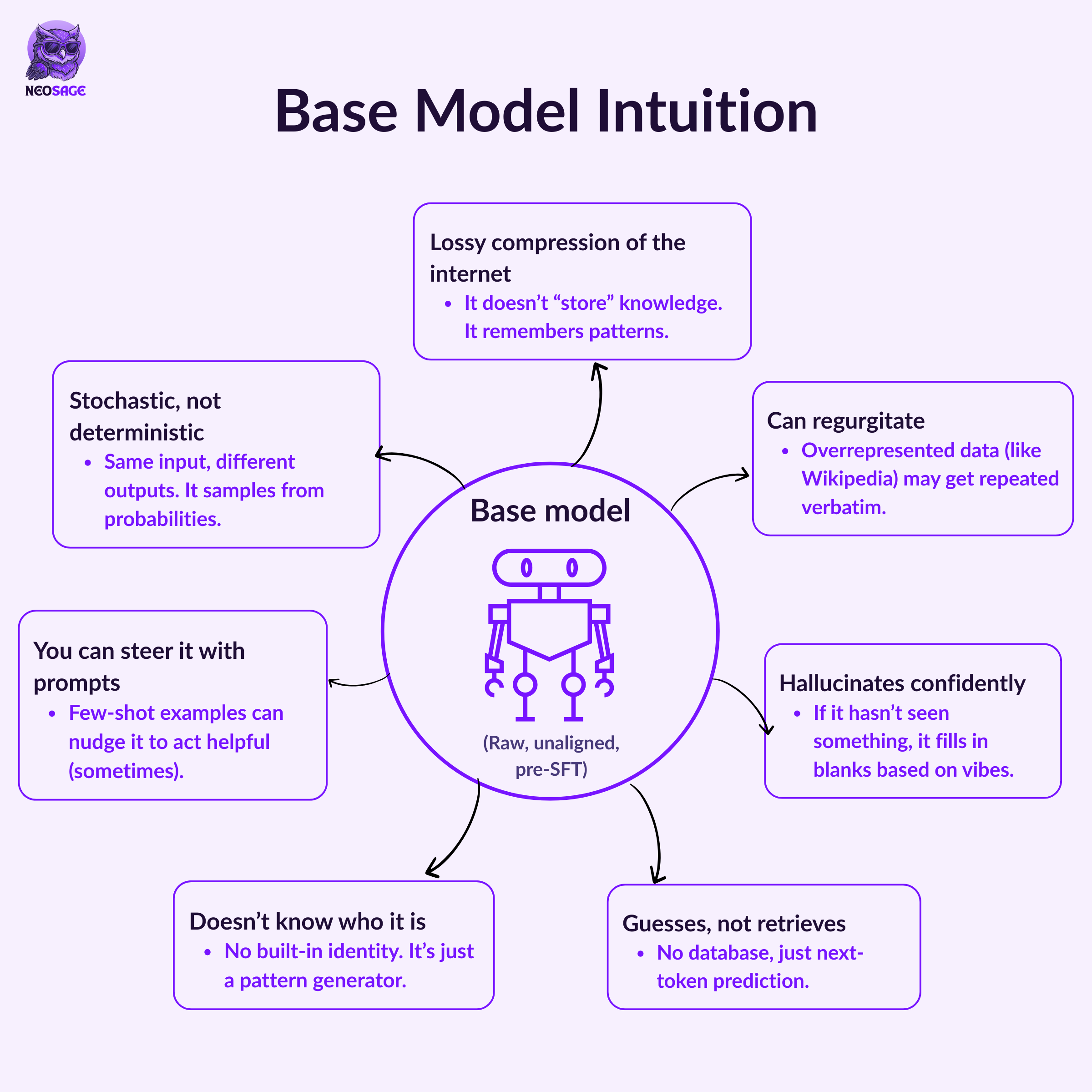
Once pretraining is complete, you get what’s called the base model.
But let’s be clear upfront:
This is not the model you interact with on ChatGPT.
The base model hasn’t been fine-tuned to be helpful, polite, or even factually consistent.
What it is… is a wildly powerful token-level internet simulator.
Its only job is to predict the next token—based purely on the statistical patterns it learned from trillions of examples during training.
That’s it.
Ask it something like:
“What is 2 + 2?”
It might not say “4.”
Because it’s not doing math—it’s just trying to complete the sentence the way it saw humans do it online.
That continuation could be a quiz, a joke, or a rant about calculators.
It all depends on its training distribution.
Here are a few key mental models to keep in mind:
1. It’s stochastic, not deterministic.
Even with the same prompt, you might get different outputs.
Why? Because the model samples from a probability distribution over possible next tokens—not always picking the same one.
2. It doesn’t “know” facts—it compresses patterns.
The model doesn’t memorize the internet.
It stores a lossy, statistical abstraction of everything it’s seen inside its billions of parameters.
Think of it like:
“What’s the most probable way a human would continue this sentence, based on a blurry snapshot of the internet?”
3. It sometimes regurgitates exact data.
Certain sources—like Wikipedia, academic papers, or popular GitHub repos—are heavily represented in training.
So if you input the beginning of a famous article or block of code, the model might complete it verbatim.
This is called regurgitation—a byproduct of overfitting on specific examples.
4. It hallucinates—often.
If you ask about something obscure, ambiguous, or poorly represented in its training data…
It may confidently make things up.
Why?
Because it’s not pulling from a knowledge base.
It’s just guessing the next token based on patterns it has seen.
5. You can still prompt it cleverly.
Even in its raw form, you can get assistant-like behavior using techniques like few-shot prompting:
“Here’s how I want you to behave. Here are a few examples. Now your turn.”
It won’t be as consistent or safe as a fine-tuned model—but this is where prompt engineering begins.
So think of the base model as the brain:
Highly capable, unfiltered, and trained to mimic the internet’s statistical style of expression.
What it’s not yet… is an assistant.
For that, we need the next step: post-training.
That’s the Brain. Next Up: The Behaviour.
By now, you’ve seen what goes into building a base model—from crawling the web to teaching it how to predict tokens like a statistical wizard.
But a base model isn’t helpful. It’s not safe. And it definitely doesn’t know when to say, “I don’t know.”
To turn this raw brain into something you can actually talk to (like ChatGPT)…
We need to teach it how to behave.
That’s what we’ll explore in the next issue:
How supervised fine-tuning teaches the model to act like an assistant
Why hallucinations still happen
What makes LLMs refuse, reason, or stumble
And how reinforcement learning adds human preference—and shapes the model’s reasoning style.
Same deep-dive, same intuition-first style—see you next week for Part 2: Teaching the Model to Behave.
References & Further Reading
If you’re curious to explore the foundational material behind this issue, here are some excellent resources I’ve drawn from:
How good is this 👏 Thanks a ton Shivani! Can't wait for the next one.
Excellent breakdown of how foundational LLMs are trained. Super well-explained.
Great work Shivani!