

The AI Application Layer: Where Context Engineering Actually Fits
Everyone is renting the same models. The work, and the value, is in what you build around them: the context window, and the three layers that decide what your model sees.

There is one word doing a lot of work this year: context engineering. It replaced last year’s favourite, prompt engineering, and somewhere in the swap, a lot of people started using both for the same blurry thing, getting the model to do what you want.
Here is the part that gets lost. A model cannot see your retrieval pipeline, your memory store, your tools, or the code you wrote to wire them together. It only ever sees one thing: the tokens you place in front of it, the context window. Your prompt, a retrieved document, a tool’s output, last turn’s reply, by the time the model reads them, they are all just tokens sitting in the same window. The window is the only reality the model has.
Once you see it that way, the buzzwords settle down. Prompting, context engineering, the harness, they are not competing trends to keep up with. They are the application layer, the part you build around the model, and underneath the labels, they come down to one job: deciding what goes into that window, and running the machinery around it. This issue maps that layer, the model that reads the window, the context that goes into it, and the harness that puts it there. And it hands you something more useful than vocabulary: a way to tell, when your system does something dumb, which of the three actually failed. Most of the time, it is not the model.
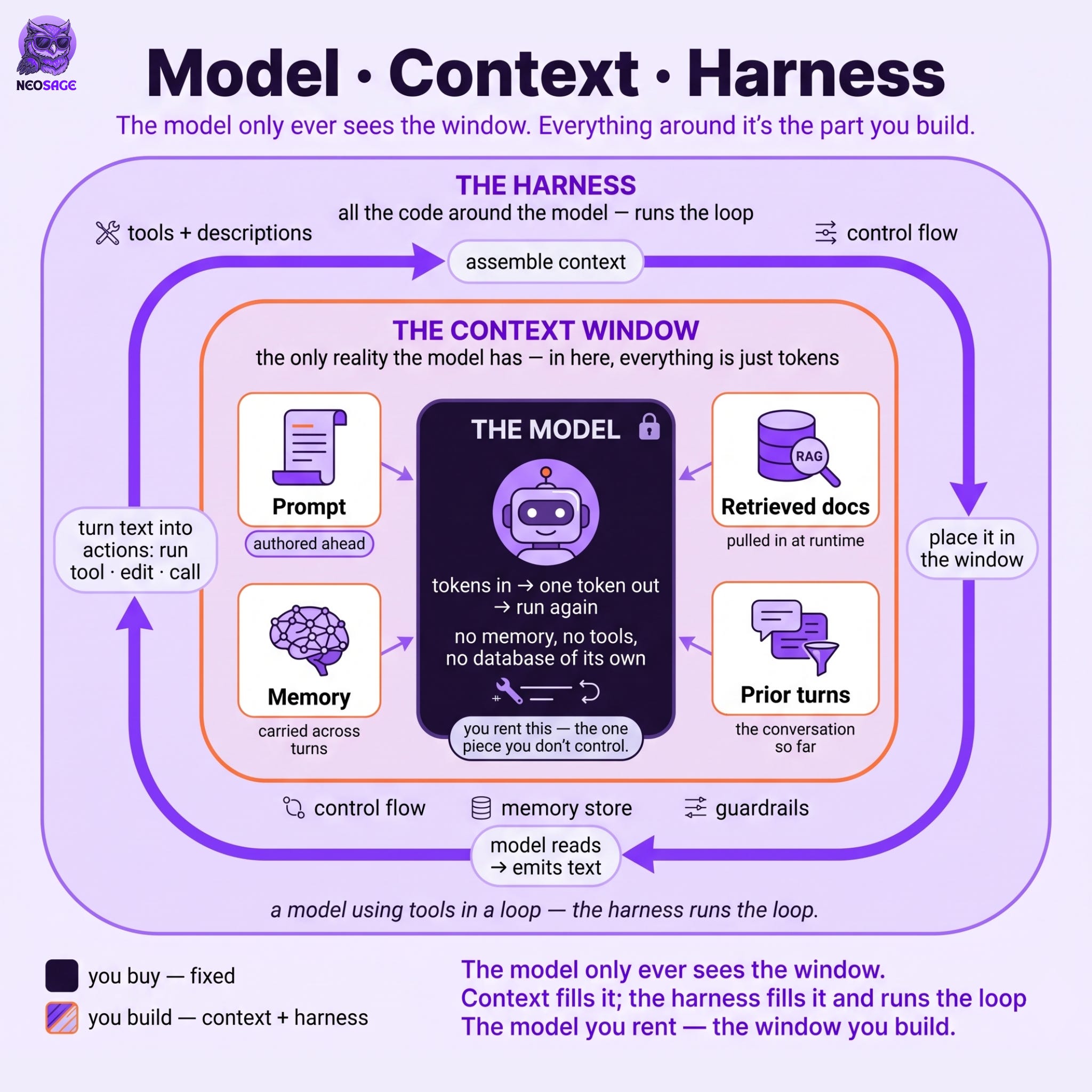
The model only ever sees the window
The model is a function. Tokens go in, one token comes out, and then it runs again with that new token added to the end. That is the whole act. It has no memory of your last session, no live connection to your database, no awareness of the tool you wired up, unless those things are sitting in the window in front of it right now.
Everything hangs on this. A model with a 200K context window is a model that can read 200K tokens, and nothing else exists to it. When someone says an agent “knows” a fact, “remembers” a user, or “can use” a tool, the real story is narrower: someone made sure the right tokens were in the window at the moment the model ran. The model reasons over whatever sits in front of it. Getting the right things in front of it is the job.
So there is only ever the window. Hold onto that, because the next three layers are all just different answers to one question: who decides what goes into it, and when.
The prompt: what you tell the model to do
Prompting has been the centre of gravity in how we talk about building with LLMs. For a while, it was the whole craft: if you wanted better output, you wrote a better prompt, a clearer instruction, a sharper example, the right format. A lot of that still holds. The prompt is where you tell the model how to behave and what its job is.
But it helps to be precise about what a prompt actually is. It is the part of the context you write ahead of time. Even when it is a template, with slots for the user’s question or the documents you pull in, the part you author is fixed scaffolding. It shapes how the model approaches the task. What it does not carry is the live information the task depends on: this user’s order history, the current state of the codebase, what was said three turns ago. That has to be gathered and placed into the window while the system runs.
That larger job, everything else that ends up in the window and how it gets there, is what the field started calling context engineering. The term did not show up because prompting was wrong. It showed up because the work got bigger than the prompt. Once a system runs over many turns, calls tools, and pulls in outside data, writing the instructions is only one slice of it. Managing the whole window became a discipline of its own.
Context engineering: choosing what the model gets to see
If prompting is how you tell the model to behave, context engineering is how you choose what it gets to see for the step in front of it. Karpathy put it cleanly: the right information, in the right form, at the right moment. Retrieval, memory, prior turns, tool results, none of it helps the model unless it lands in the window, and the skill is deciding what makes the cut.
The instinct, the moment you have a 200K or a million-token window, is to use the room. Retrieve more documents. Keep the whole history. Hand the model everything and trust it to find what matters. That instinct is wrong, and we now have the numbers to show why.
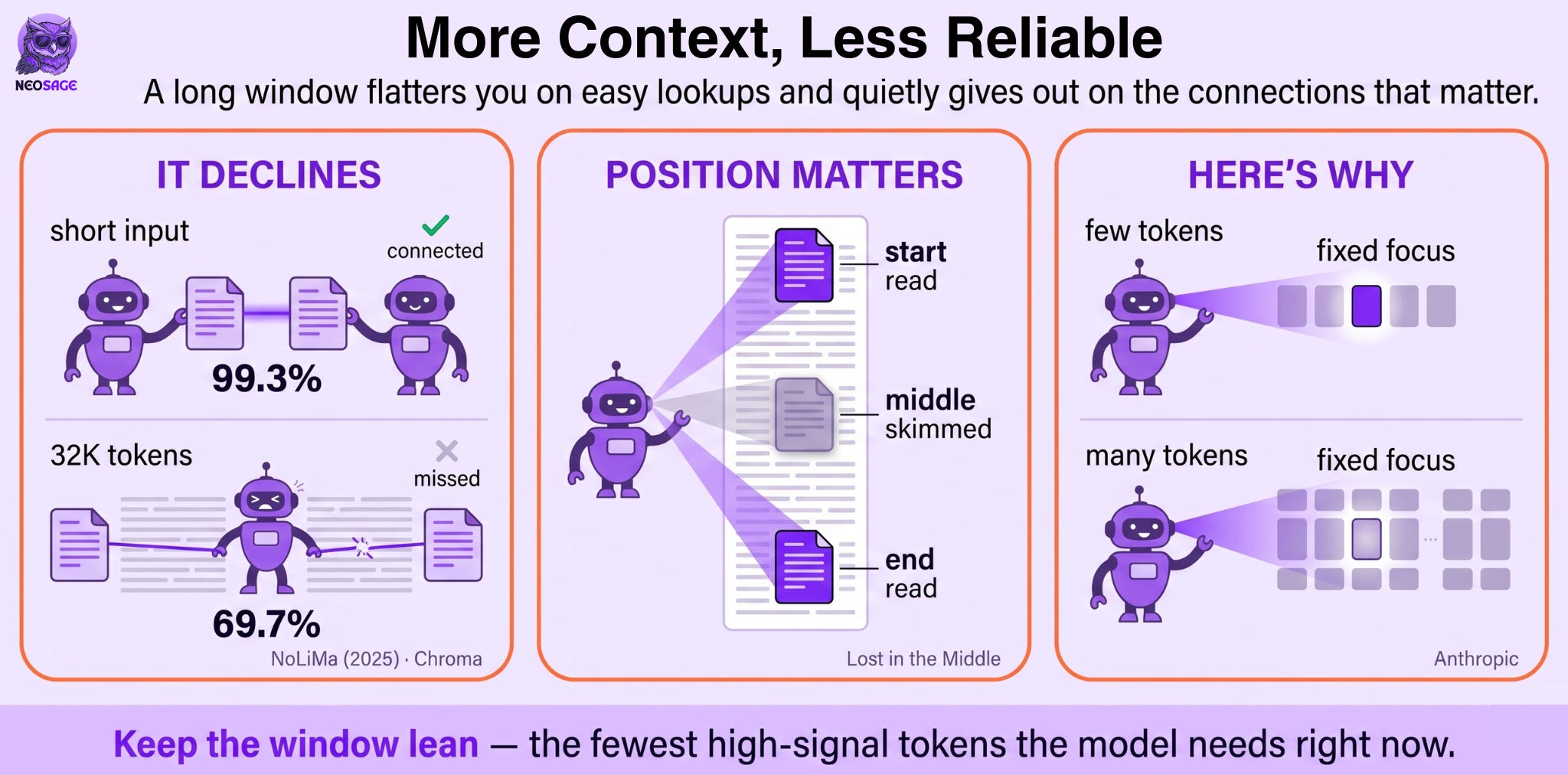
The clearest evidence comes from a 2025 study called NoLiMa, and it starts by exposing a flaw in how long context is usually tested. The standard test buries a fact in a big pile of text and asks the model to fetch it, but in most of these tests the question is worded much like the sentence that holds the answer. That overlap is a giveaway. The model can land on the answer by surface resemblance, the way a familiar phrase jumps out at you while skimming, without having to work out what the text actually means. Real tasks rarely hand you the answer in the same words as the question, so NoLiMa took the overlap away: it wrote the question and the answer to share no wording, which left the model no choice but to connect the meaning to find it.
That one change is revealing. On a short input, GPT-4o makes that connection almost every time, on 99.3% of the questions. Give it the same kind of task at 32K tokens and it falls to 69.7%. Same model, same kind of question. What changed is the distance: the more text the model is holding at once, the harder it becomes to connect two ideas that sit far apart inside it. And connecting ideas across the context is exactly what real work asks of it. A long window flatters you on easy lookups, where the answer is sitting right where you expect it, and quietly gives out on the connections that actually matter.
Where a fact sits in the window matters too, not just how much surrounds it. In a well-known experiment called Lost in the Middle, researchers put the answer to a question at different spots inside a long context and watched what happened. When the answer sat near the start or the end, the model usually found it. When it sat in the middle, the model often missed it, sometimes doing worse than if it had been handed no document at all. Models lean hardest on the edges of their context and tend to skim what is in between, so a key fact buried halfway in can simply get passed over.
And this decline is not a cliff you can avoid by staying under some token count. It is gradual. A study from Chroma showed that as the input grows, performance slips little by little, even on tasks the model breezes through when they are short. There is no safe length where quality holds steady and then suddenly breaks. It erodes the whole way up. More text, a little less reliable, every time.
Why does any of this happen? It comes down to how attention works. To decide what to focus on, the model weighs every token in the window against every other one. When there are only a few thousand tokens, the handful that matter can stand out. Pour in a few hundred thousand, and that same attention has to spread across all of them, so the tokens you care about get a thinner and thinner share of the model’s focus. Anthropic calls this an attention budget: the model has a fixed amount of attention to spend, and every token you add spends a little of it. Past a point, extra context stops helping and starts competing with the parts that actually matter.
So the real job is not stuffing the window. It is the opposite: keep it lean, hold the fewest high-signal tokens the model needs right now, and keep the rest out of the way until it is needed. A handful of moves do most of that work:
Pull information in only when it is needed. Instead of loading everything up front, hold lightweight pointers, a file path, a saved query, and fetch the real content at the moment the task calls for it.
Compact long sessions. When a conversation nears the window limit, replace the older turns with a summary that keeps the decisions and the open problems, and continue from there. The full history can still live in storage if you need to go back to it, the window just carries the compressed version, so it is a tradeoff of detail for room, not a permanent loss.
Clear tool results once they are used. After the model has read a bulky tool response, you can swap it out of the window for a short placeholder. The data is not gone; it is still on disk, and the model can fetch it again. It just stops taking up space the model has to read on every turn.
Keep the goal in view. On a long task, restate the current objective near the end of the window, where the model’s attention is strongest, so it does not drift from what it set out to do.
There is a cost side too. For a lot of agents, the model reads far more than it writes. At Manus, a typical run takes in around 100 tokens for every 1 it produces. The exact ratio depends on what the agent does; a coding agent that writes long files looks different, but for most retrieval-heavy and long-running agents, the input dominates, which is where the money goes. And input tokens are not all priced the same: a token the model has already cached costs roughly a tenth of a fresh one. So how you manage context is quietly a 10x cost decision, not just an accuracy one. Keep the start of your window stable and only add to the end, and the cache keeps paying off. Change something early, and the model has to re-read everything after it at full price. Manus came to a blunt conclusion: for a production agent, your cache hit rate is the single most important number to watch.
Context engineering, then, is curation under two pressures at once, the model’s attention and your bill, and both push the same way: the right tokens, as few as you can manage, in an order that lets the model find them and the cache keep them.
The harness: the loop that runs the whole thing
Everything we just walked through, pulling information in, summarising, clearing, deciding when to call the model and what to do with its answer, has to be run by something. That something is the harness: all the code around the model that is not the model itself. The tools and their descriptions, the control flow, the memory, the guardrails, and the loop that ties them together.
The simplest honest definition of an agent is a model using tools in a loop, where the result of each action feeds the next decision. The harness is what runs that loop.
Picture a coding agent fixing a failing test. The model says, “run the tests.” The harness actually runs them, catches the output, and decides how much of it to put back in the window. The model reads the failure, says “edit this file,” and the harness makes the edit, reruns the tests, and feeds the new result back. Round and round, until the tests pass or the harness decides to stop. The model never touched a file or ran a command. It only ever produced text. The harness turned that text into actions and turned the results back into context for the next turn. That loop is the agent.
This is also where a whole class of failures lives, the ones that look like the model being dumb but are not. Cognition, the team behind the Devin coding agent, found that Devin would start cutting corners when it believed it was running low on context room, even when it had plenty left. They had to manage that through how the harness reported the situation back to it. They also found that splitting work across several agents quietly broke things, because each agent was acting on context the others could not see, and their assumptions silently conflicted. The fix was to keep one continuous thread and pass the full history along, instead of scattering it across workers. None of that is the model lacking ability. It is the harness handing it the wrong situation.
The harness is where your system’s behaviour actually lives. The model gives you intelligence in fixed units. The harness decides how often to call on it, what to show it each time, and how far to trust what it sends back.
The map, and how to use it
Put the three together, and the picture is simple. There is the model, which reads the window. There is the context that goes into that window, the prompt you wrote plus everything the system pulled in around it. And there is the harness, which does the pulling-in and runs the loop. The model is the one piece you do not control. Almost everything you do control is context and harness.

That is not just a tidy diagram; it is how you debug. When an agent does something wrong, the reflex is to ask whether the model is smart enough. Sometimes that really is the answer; a task can sit beyond the model you picked. But far more often, the model was capable, and something around it failed, and the map tells you where to look. Walk it in order:
Did you ever tell it? If the model was never given the rule, the format, or the constraint it broke, that is a prompt problem. The fix is in what you wrote.
Was the right thing in the window, and could the model find it? If the fact it needed was never retrieved, or it was in there but buried under ten thousand tokens of noise, that is a context problem. The fix is in what you assemble, and how much.
Did the loop mishandle it? If the information was right there and the model still went wrong, because the harness fed back the wrong tool result, dropped a detail three turns ago, or pushed it to rush, that is a harness problem. The fix is in the machine, not the model.
Run those three in that order, and most “the model is dumb” moments turn out to be “the window was wrong” or “the loop was wrong.” That is what the stack buys you: you stop arguing with the model’s intelligence and start fixing the thing that actually broke.
The window is the part you build
Strip the vocabulary away, and one idea is left standing: the model only ever has the window, and your whole job is what goes into it and what runs around it. Prompting, context engineering, harness engineering are not three trends to keep up with. They are three places to stand when you decide what the model sees, and three places to look when it gets something wrong.
The teams shipping the best agents right now are not the ones with secret access to a smarter model. Everyone is renting the same models. The edge is in the application layer, everything you build around the model, and the teams that win treat the window as the scarce, expensive, easily-wrecked thing it is, and build around it on purpose. The model, you buy. The window, you build.

Give a person a bigger desk and they tidy up. Give an engineer a bigger context window and they hoard. Then the model misses the one line that mattered, buried under three hundred thousand tokens of just-in-case, and the postmortem says the model got dumber. It didn’t. You asked it to find a whisper in a stadium, then blamed it for the crowd. Bigger window, same attention. You just gave it more to tune out.
Stay dangerous. Hoot. — Nocto
If this changed how you look at your own stack, hit reply and tell me what you’re building.