

The Engineer’s Guide to RAG
Make Your Dumb Model Useful: A Dead-Simple Guide to Retrieval-Augmented Generation

Modern LLMs are powerful — but they’re also static.
Once a model is trained, it can’t learn anything new.
No internet. No updates. No awareness of your internal docs, customer tickets, or product features.
That’s because language models aren’t knowledge bases.
They don’t “look up” information.
They predict the next token based on patterns seen during training, and that training ended months ago.
Yet in real-world systems, most queries aren’t about abstract language patterns.
They’re about your data.
What’s our refund policy?
What did the customer say in the last chat?
What does this API do?
These are context-dependent questions.
And answering them requires injecting the right context at the right time.
That’s where Retrieval-Augmented Generation (RAG) comes in.
This issue is your technical blueprint.
We’ll walk through:
Why static LLMs fall short
Why fine-tuning isn’t always the fix
And how RAG lets your model access fresh, dynamic, grounded context, without touching a single weight
By the end, you won’t just understand RAG.
You’ll know when, how, and why to use it in production.

The Real Problem
LLMs aren’t dynamic systems.
They’re static functions — mapping input tokens to output tokens based on frozen training data.
This has two major consequences for real-world applications:
1. They can’t access private or real-time information.
Your model might be brilliant at writing SQL —
But it knows nothing about your schemas, tables, or naming conventions.
It might be great at summarising —
But it can’t summarise your product docs if it’s never seen them.
2. They hallucinate confidently when they don’t know.
LLMs are next-token predictors.
When they lack relevant context, they don’t say “I don’t know.”
They interpolate. And that often leads to fabricated answers, which look fluent but fail under scrutiny.
This isn’t a bug — it’s a design constraint.
A pretrained model is a static snapshot.
If your application needs current, personalised, or proprietary knowledge, you need to pipe that knowledge in at inference time.
That’s the core challenge RAG is designed to solve.
But before we get to RAG, let’s zoom out and explore all the ways builders try to solve this data gap.
Why Prompting and Fine-Tuning Can’t Solve the Knowledge Gap
Once you realise your model doesn’t know your product, your user history, or your internal docs, the next question is:
How do we teach it?
There are multiple strategies to work with LLMs in the application layer, two of which are:
Prompt Engineering and Fine-Tuning.
Both can be powerful, but neither truly solves the problem we’re dealing with:
Giving a frozen model access to dynamic, user-specific, or time-sensitive knowledge.
Let’s step through them.
1. Prompt Engineering — Helpful, But Limited
Prompting is about shaping the model’s behaviour at inference time.
You’re not teaching it new facts — you’re teaching it how to respond based on what it already knows.
Prompt engineering is useful for:
Formatting answers
Steering tone and voice
Guiding reasoning (e.g. Chain-of-Thought, ReAct)
Enforcing structure (e.g. JSON output, few-shot examples)
But here’s the core limitation:
Its primary role is to guide how the model behaves — any data you add to the prompt improves response quality, but sourcing that data isn’t what prompt engineering solves.
It might be easy to confuse prompt engineering with prompt augmentation.
But adding new context into the prompt, like search results or documentation snippets, is a separate step.
That’s not prompt engineering.
That’s prompt augmentation — and that’s what RAG is built to automate.
So while prompt engineering improves fluency and structure, it does nothing for grounding the model in your data.
2. Fine-Tuning — Powerful, But Inflexible
Fine-tuning is about modifying the model’s weights.
You take a base model and train it further on new examples — either task-specific, domain-specific, or instruction-style.
This helps in scenarios like:
Teaching the model legal or medical terminology
Improving performance on repetitive, structured workflows
Adapting to company-specific language or formats
But in the context of our core problem — giving a model access to live, evolving, or user-specific data — fine-tuning has major limitations:
❌ It’s slow and costly — requires GPUs, training infra, and QA cycles
❌ It’s brittle — every update means retraining or risking drift
❌ It’s static — the model remains locked after each fine-tune
❌ It’s inflexible — different users or contexts need different versions
Fine-tuning is best when your knowledge is stable and your tasks are narrow.
But it falls apart when you want a model to respond to:
“What’s the latest version of our API docs?”
“What did this customer say in their last ticket?”
“What changed in the HR policy last week?”
That’s not a training problem.
That’s a retrieval problem.
And that brings us to the solution this issue is all about — one that doesn’t update the model at all, but updates what the model sees at runtime.
Let’s talk about RAG.

So What Is RAG?
At its core, Retrieval-Augmented Generation (RAG) is a simple but powerful pattern:
Instead of retraining the model, you retrieve relevant information from an external source and inject it into the prompt — at inference time.
That’s it.
No gradient updates.
No fine-tune cycles.
Just smarter input.
Here’s the distinction that matters:
The model remains frozen — it still runs the same next-token prediction function.
What changes is the context window:
You augment it with fresh, task-relevant knowledge pulled from a database, knowledge base, or internal document store.
In other words:
RAG doesn't teach the model.
It feeds it better inputs — right when it needs them.
This makes RAG fundamentally different from:
Fine-tuning (changes the model)
Prompt engineering (tweaks behaviour)
Tool use (delegates tasks)
RAG treats the model as a black box and solves the problem outside it.
It shifts the system design from "How do I modify the model?" to
"How do I retrieve and inject the right context before the model answers?"
This single shift unlocks:
Real-time updates without retraining
Personalisation per user/session
Seamless integration of internal knowledge
But it also introduces a new bottleneck:
Your model is now only as good as what you retrieve and what you stuff into the context window.
RAG moves the complexity from training to retrieval.
That’s not a simplification — it’s a re-architecture.
What RAG Really Does
At its simplest, RAG (Retrieval-Augmented Generation) does three things:
Retrieves the most relevant data based on your question
Augments the LLM’s prompt with that data
Generates a grounded response using both the query and retrieved context
You’re not teaching the model anything new.
You’re giving it just enough information to answer the question as if it knew.
That’s it.
Imagine ChatGPT — but before it responds, you hand it a Post-it Note saying:
“By the way, here’s what our refund policy says.”
And then it writes the answer. That’s RAG.
The Retrieval-Augmented Loop
Now let’s step through what’s actually happening under the hood.

Step 1: User Query
The user asks a question in plain language:
“What’s our refund policy for digital products?”
At this point, the model on its own doesn’t have a clue.
It wasn’t trained on your policy docs.
So instead of letting it hallucinate —
we retrieve the answer from a trusted source.
Step 2: Embed the Query
We convert the user’s query into a vector — a dense numerical representation that captures semantic meaning.
This is called an embedding.
The sentence “refund for digital orders”
might produce a vector like
[0.22, -0.87, 1.03, ...]— 768+ numbers long.Another sentence like “return policy for ebooks” would produce something nearby in vector space.
These vectors aren’t based on keywords — they’re based on meaning.
Embeddings let us match “What’s your refund policy?”
to a sentence that says, “Customers can request a refund within 7 days of purchase.”
That’s how semantic search works — it’s meaning-based, not string-based.
Step 3: Vector Search Over Your Corpus
We now search this query vector against a vector database, like Weaviate, Qdrant, Pinecone, or FAISS.
But this database doesn’t store raw documents.
It stores pre-chunked, pre-embedded pieces of your knowledge base, such as:
Individual help articles
Paragraphs from your product manual
Snippets of legal policy text
Past conversations or support threads
Each one is already embedded as a vector.
Now we calculate which of those vectors are closest to our query in vector space.
This is where “top-K retrieval” happens. We fetch the K most semantically similar pieces of content.
Step 4: Return Top-K Chunks
Let’s say your query embedding matches 3 chunks closely:
“Refunds for digital products must be requested within 7 days.”
“Refund requests can be submitted via dashboard or email.”
“Physical products have a 30-day return window.”
These chunks are returned, often with scores.
In basic setups, we stop here.
But in smarter systems, we might apply:
Re-ranking: to push the most relevant one to the top
Filtering: to remove irrelevant ones
Scoring models: to judge answerability
More on those in a minute.
Step 5: Inject Into Prompt
These retrieved chunks are then formatted and injected directly into the LLM’s prompt.
It might look like this:
Context:
1. Refunds for digital products must be requested within 7 days.
2. Refund requests can be submitted via dashboard or email.
Question:
What’s our refund policy for digital products?To the model, this is just part of the input.
It has no idea it came from retrieval — it just treats it like any other text.
Step 6: LLM Responds Grounded in That Context
The LLM reads the entire prompt — your system instructions, the context chunks, and the query.
Then it does what it always does:
predict the next most likely tokens.
But now, because the context window contains the right information, the response is grounded:
“Customers can request a refund for digital products within 7 days of purchase. You can do this via dashboard or by email.”
No hallucination. No guessing.
Just answering with what you gave it.
And in Smarter RAG Systems?
The flow stays the same, but we enhance individual steps to boost relevance and reliability.
Advanced RAG systems often include:
Re-ranking: Using a second model (e.g. cross-encoder) to rescore and reorder the top-K chunks
Query rewriting: Transforming vague or underspecified user queries into more precise ones
Chunk scoring: Assessing how well a chunk answers the question before injecting it
Context pruning: Removing low-value or redundant content to save tokens
Routing models: Choosing between different knowledge sources, agents, or workflows dynamically
These are not optional tricks — they’re often what separates production-ready RAG systems from toy demos.
Data Is God

Once you understand how RAG works, it’s tempting to think the model is doing the heavy lifting.
But here’s the truth:
The model just fills in blanks.
The real work happens before the prompt is ever built.
If your retrieval layer is weak, your output will be wrong, no matter how smart your LLM is.
That’s why in production-grade RAG, preprocessing and ingestion are the hardest and most critical steps.
What Makes or Breaks a RAG System?
Let’s rewind the loop from earlier:
Your user asks a question.
The retrieval system tries to find the most relevant information.
If it fails, the model fails.
So what decides whether retrieval succeeds?
How you structure and prepare the data.
This is the part no demo talks about.
Why Indexing Isn’t Enough — You Need Ingestion
Most people think:
“We’ll just chunk our docs and push them into Pinecone.”
That’s not ingestion. That’s dumping.
Proper ingestion is curation, segmentation, and semantic structuring.
You need to:
Clean the content (remove footers, junk text, irrelevant sections)
Split intelligently (not just every 500 characters)
Preserve relationships (e.g. question + answer, section + header)
Tag metadata (source, author, timestamp, type)
Embed using the right model (some are better for short queries, others for long-form)
Chunking: The Hidden Minefield
Most RAG failures come down to bad chunking.
If your chunk is:
Too long → it never gets retrieved
Too short → lacks meaningful context
Split mid-sentence → loses meaning
Contains dense code/docs → model can’t parse structure
…you’re injecting garbage into the prompt.
And remember:
LLMs don’t reason over your entire corpus.
They only see the few chunks you retrieved — in a window capped by token limits.
If those chunks are bad, it’s over.
Embeddings: Not All Are Equal
The purpose of an embedding model is simple, but critical:
To map semantically related inputs close together in vector space, so that a query retrieves meaningfully relevant chunks.
But semantic relationships aren’t fixed — they shift with domain, task, and context.
In general-purpose domains, off-the-shelf models like OpenAI’s text-embedding-3-small might work:
“Refund policy” and “money-back guarantee” might be embedded closely
“Cancel subscription” and “stop membership” land nearby
But in your company’s knowledge base?
“Workflow” might mean approval rules in legal, automation in ops, or DAGs in engineering
“Runbook” could refer to on-call procedures or ML model deployment steps
These distinctions don’t exist in general language models — and they won’t be captured in their embeddings.
That’s when off-the-shelf breaks down.
To retrieve the right chunks, your embedding space needs to reflect your world, not just the internet’s.
And that’s where fine-tuned embedding models come in:
Aligned to your jargon, naming conventions, and relationships
Trained to treat “access token” and “JWT” as close, if that’s how your org writes
Able to embed meaning that’s invisible to a model trained on Stack Overflow and Wikipedia
So yes, vector search works.
But without embedding models that understand your context, you’re just retrieving based on someone else’s semantics.
And that’s where most RAG pipelines silently fail.
Metadata + Filtering = Precision
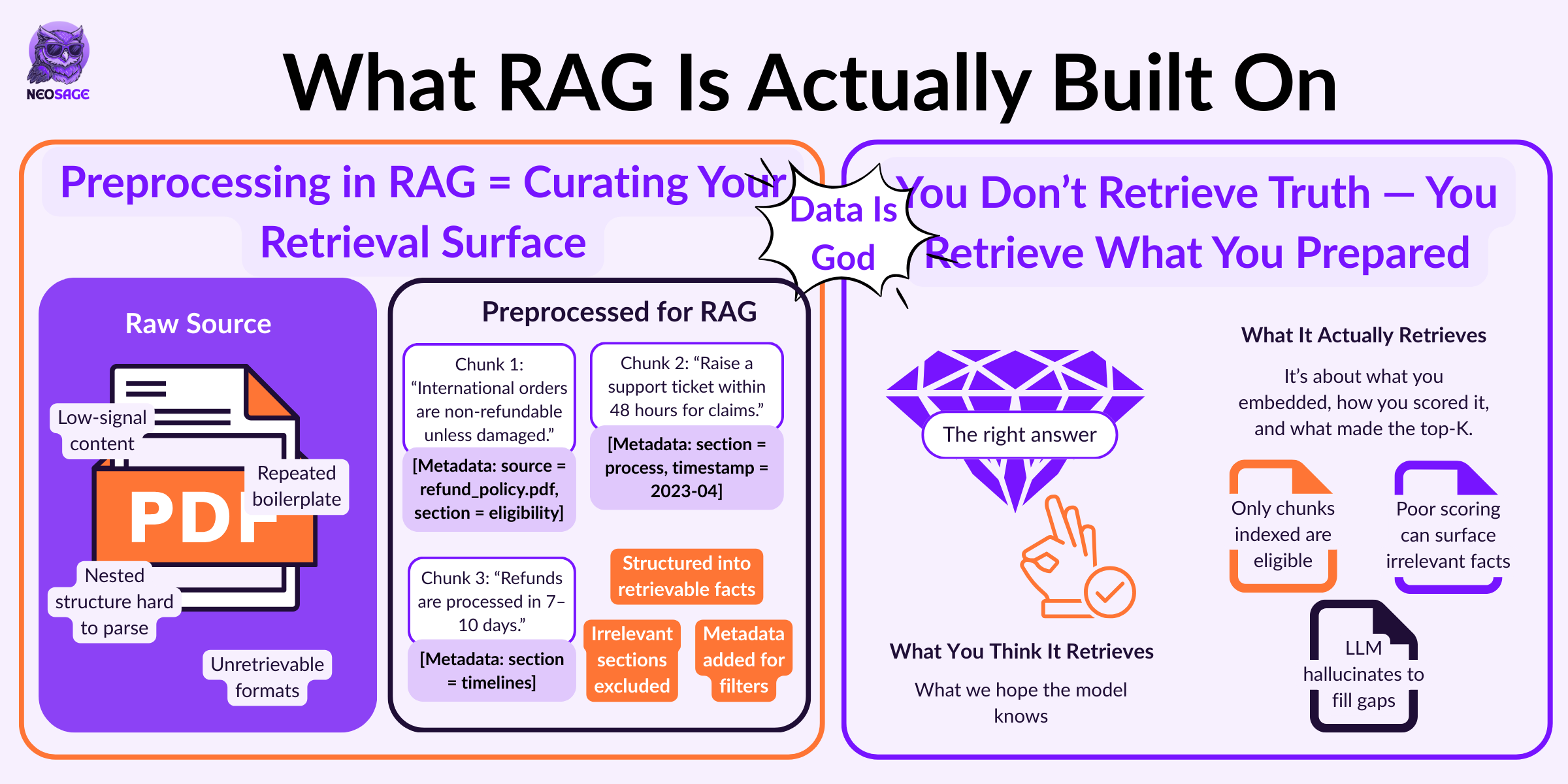
RAG gets exponentially better when you add:
Document-level metadata (source, product, region, date)
Filters to narrow down scope (e.g., “only look at API docs”)
Hierarchical indexing (parent-child chunking with recall context)
Why?
Because relevance isn’t always semantic. Sometimes it’s structural.
“Refund policy” may match 20 pages —
But only the one from 2024, authored by Legal, is correct.
RAG Is Not Plug-and-Play
In simple demos, RAG looks magical. Ask a question → get a grounded answer.
But in production?
RAG is a data engineering problem disguised as an NLP trick.
And the teams who succeed with it are the ones who:
Treat document ingestion like software engineering
Own their preprocessing pipeline like an ML pipeline
Monitor retrieval quality, not just model latency
So yes, LLMs are powerful.
But in RAG?
The system only works if your index is a reflection of reality.
And building that index… is where the real engineering lives.
Where RAG Fails (And Why It’s Not Magic)
At this point, RAG might sound like the cleanest solution to the static LLM problem — and in many ways, it is.
But here’s the real picture:
RAG isn’t a silver bullet. It’s a layered system — and every layer can break.
Let’s walk through the most common failure points.
1. Relevant Chunk Not Retrieved → Irrelevant Answer
This is the most frequent failure mode — and the easiest to miss.
If the retriever doesn’t surface the right chunk, the LLM will confidently answer using whatever is closest, even if it’s wrong.
You’ll see:
Outdated policies getting returned
Answers pulled from unrelated but similar-sounding chunks
Hallucinated claims based on misleading context
What’s broken here isn’t the model.
It’s retrieval quality, and that’s downstream of bad chunking, poor embeddings, or inadequate metadata filtering.
2. Model Gets the Right Context — But Ignores It
Sometimes the retriever does its job.
You get the right chunk. The context is injected. Everything looks good.
But the answer?
Wrong, generic, or completely detached from the provided data.
What’s happening here?
The model isn’t grounded. It’s guessing — blending pretrained knowledge with your context instead of sticking to it.
This happens when:
There’s no clear instruction to use only the retrieved content
The question is vague, but the context isn’t enforced
The model’s prior training overrides the injected source
The result: plausible answers that contradict your ground truth.
This is especially dangerous in compliance or legal workflows, where hallucinating within context is worse than not answering at all.
RAG isn’t just retrieval. It’s retrieval plus constraint.
Without both, you’re just helping the model hallucinate better.
3. Semantic Mismatch Between Query and Chunk
This one’s harder to spot.
Let’s say your index includes:
“Users are entitled to a full refund within 7 days.”
But the user asks:
“Can I cancel and get my money back?”
If your embeddings or retrieval method can’t connect “cancel” → “refund”, or “money back” → “entitled”,
→ That chunk won’t surface.
This is where language gaps, jargon, and undertrained embedding models create false negatives.
It’s not about bad data. It’s about a missed semantic bridge.
4. Information is Split Across Chunks
Sometimes the answer isn’t in a single chunk — it lives across two or three.
E.g.:
Chunk A says: “Refunds available for digital products.”
Chunk B says: “Refunds must be requested within 7 days.”
Both are required for a full answer.
But standard (naive) RAG systems don’t do multi-hop synthesis well, especially if chunk order isn’t preserved or coherence is lost in truncation.
Unless you’ve designed your chunking and scoring to preserve continuity,
→ You get partial answers, or worse, confident contradictions.
5. The Right Data Isn’t in the Index at All
This is a classic ingestion blind spot.
Sometimes, the most relevant information:
Lives in a format you didn’t ingest (e.g. image-based PDFs, buried tables, raw HTML)
Was missed due to bad parsing
Was updated in the source system, but your index is stale
RAG can’t retrieve what isn’t there.
That’s why index observability and refresh strategies are part of any serious RAG system — not just “nice to have.”

RAG Doesn’t Fail Loudly — It Fails Silently
And that’s the danger.
Unlike traditional software bugs, most RAG failures look like they worked:
The model gives an answer
It’s grammatically correct
It sounds plausible
But it’s wrong. And it’s grounded in the wrong data.
So you need to build for:
Retrieval monitoring
Prompt observability
Failure evaluation beyond accuracy metrics
Because in RAG, silence isn’t success.
It might be a confident lie — and that’s the hardest kind to debug.
Beyond Just Docs — Smart RAG Systems
At this point, it’s clear:
Naive RAG breaks in all the places that matter.
It retrieves the wrong thing. Or it retrieves the right thing and still gives the wrong answer.
It doesn’t know when to say “I don’t know.”
It doesn’t improve over time.
But that’s not the limit of what RAG can be.
Let’s talk about how smart systems fix it.
The Mental Shift
Most people think RAG = “vector search over some docs.”
But in production, RAG becomes an optimisation problem:
How do we consistently retrieve the most useful, most answerable context — while minimizing noise, cost, and latency?
Smart RAG systems don’t just retrieve.
They rank, filter, score, adapt, and learn.
Let’s walk through the upgrades that transform fragile RAG into robust retrieval-first infrastructure.
1. Hybrid Retrieval Fixes Semantic Blind Spots
Problem it solves:
Vectors alone miss exact matches, rare entities, and domain-specific tokens.
Fix:
Use both:
Dense retrieval (for semantic similarity)
Sparse retrieval (BM25 or keyword scoring for exact matches)
This immediately improves:
Retrieval precision on short, vague queries
Performance on identifiers (like error codes, SKUs, names)
Hybrid retrieval makes your system semantic and literal — exactly when it matters.
2. Re-ranking Models Pick the Right Top-K
Problem it solves:
Top-K based on cosine similarity ≠ most useful chunks.
Fix:
After initial retrieval, use a cross-encoder (like Cohere Rerank or BGE-Reranker) to rescore the candidates for:
Factual match
Answerability
Coverage
This reranking happens before prompt injection, and it massively reduces hallucinations.
Smart RAG doesn't just ask “what’s similar?”
It asks: “what actually answers the question?”
3. Metadata Filtering Reduces Retrieval Scope
Problem it solves:
Retrieving from everything leads to irrelevant or outdated context.
Fix:
Leverage metadata added during ingestion:
product_version = "2.1"source = "legal"created_at >= last_month
This constrains search to what’s actually relevant before you rank.
Your data isn’t flat. Treating it like it is kills precision.
4. Semantic Chunking Improves Retrieval Quality
Problem it solves:
Poor chunking creates semantically meaningless embeddings.
Fix:
Don’t split blindly every N tokens. Instead:
Chunk by sections, paragraphs, headings
Use sentence boundary detection
Keep context units (e.g., question+answer, method+docstring) together
Optional: Add contextual overlap and parent references for coherence.
You’re not embedding text. You’re embedding meaning units. Chunk accordingly.
5. Retrieval Feedback Loops Make the System Learn
Problem it solves:
You don’t know which chunks actually helped the LLM answer well.
Fix:
Track:
Which chunks were injected
Whether the response was accepted/clicked
Retrieval-to-output overlap (did the model use the retrieved info?)
Then:
Up-rank useful chunks over time
Down-rank misleading ones
Use hard negatives to fine-tune better embeddings
RAG isn’t static. If it doesn’t learn, it decays.

Advanced Patterns (When You’re Ready to Scale)
Once your retrieval foundation is solid, these advanced patterns can unlock more robust and intelligent behaviour:
Multi-Query RAG
→ Reformulates a single user query into multiple semantic variants, retrieves for each, and merges results.
Boosts recall for vague or underspecified questions, especially in sparse or noisy corpora.
Knowledge Graph-Augmented RAG
→ Uses a graph of entities and relationships to guide retrieval.
Enables structured reasoning, cross-doc linking, and retrieval based on relationships, not just raw text.
Multi-Agent RAG
→ Chains specialised agents (retrievers, verifiers, planners) to dynamically reformulate queries, rerank chunks, and validate answers.
Useful for multi-hop queries, tool integration, and dynamic workflows.
These are not required to get started — but they represent the future of RAG at scale.
Evaluating RAG Systems — The RAG Triad Framework
Building a RAG system is one challenge.
Knowing if it works — that’s a different problem.
And here's where most teams go wrong:
They evaluate the model’s answer, not the retrieval system behind it.
That’s like debugging a recommendation engine by checking if the “Buy” button was clicked, without knowing what products were shown.
RAG needs its own evaluation lens.
And that’s where the RAG Triad Framework comes in.
The RAG Triad
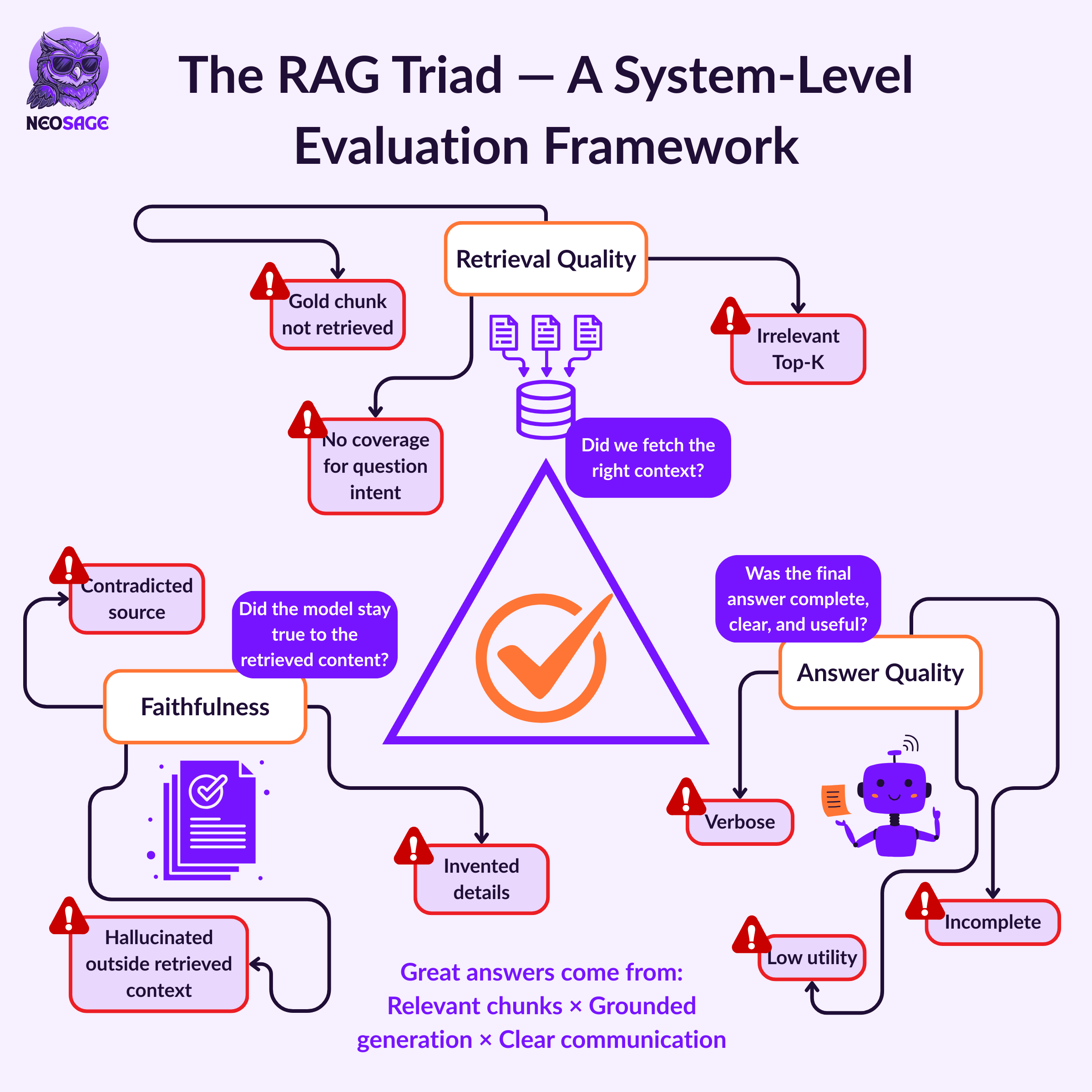
To truly evaluate a RAG pipeline, you need to assess three interdependent components:
Retrieval Quality
Faithfulness
Answer Quality
These are distinct, and failures in one don’t always show up in the others.
Let’s break them down.
1. Retrieval Quality
“Did we fetch the right context in the first place?”
The first test of any RAG system is whether the retriever surfaced the relevant, sufficient, and necessary information for the query.
Key metrics:
Recall@k: Was the gold/relevant chunk in the top-k retrieved?
Precision@k: Of the chunks retrieved, how many were actually relevant?
Retrieval overlap: Did the model actually use any of what was retrieved?
How to measure:
Human-labelled gold chunks (if available)
Embedding-based similarity to expected answer
Heuristic filters like answer-span matching
Without good retrieval, the model is guessing.
Bad retrieval = good prompt = bad answer.
2. Faithfulness
“Did the model stay true to the retrieved context?”
RAG was supposed to fix hallucination.
But if your model mixes retrieved content with pretrained priors, it’s just inventing grounded-sounding fiction.
Key metrics:
Context overlap: Does the answer contain text or meaning from retrieved chunks?
Faithfulness score (via QA or entailment models): Does the answer only use supported info?
Contradiction flags: Does the output contradict any retrieved source?
How to measure:
Use natural language inference (NLI) models to compare output vs. context
Extract claims from outputs and check if they are supported by any chunk
Human eval with source checking
This is not about correctness — it’s about alignment with the context.
A factually wrong answer that used the context correctly is a retrieval issue.
A factually wrong answer that ignored context is a generation issue.
3. Answer Quality
“Was the final answer useful, clear, and complete?”
This is the traditional metric most teams already focus on:
Fluency
Task completion
Helpfulness
Hallucination (at the output level)
Key metrics:
ROUGE/BLEU/METEOR (if ground truth exists)
Judgmental scores (e.g. helpful/unhelpful from human labelers)
LLM-as-a-judge methods (scoring based on criteria)
But answer quality without retrieval traceability is deceptive:
A “great” answer from hallucinated data is a future failure waiting to happen.
Why the Triad Matters
Evaluating just the final answer is like checking the tip of an iceberg.
A fluent answer that sounds right could still be completely wrong, because either:
The wrong chunk was retrieved (retrieval failure)
The model ignored the context and guessed (faithfulness failure)
Or the answer, while correct, was vague or incomplete (answer quality failure)
Here’s the mental model:
If retrieval fails, the model never had the right info to begin with. If faithfulness fails, the model had it — but didn’t use it. If answer quality fails, the system did everything right — but failed to communicate.
You don’t fix these by “prompting better” or “changing the model.”
You fix them by diagnosing the exact stage that broke, and improving that layer of the system.
That’s what the RAG Triad lets you do:
treat RAG as a system, not a monolith.
Congratulations you’re no longer a Noob. You’re a Builder.
You didn’t just read about RAG.
You rebuilt how you think about it, layer by layer.
You now know it’s not a trick to bolt onto a chatbot.
It’s an architecture that lives or dies by how well you:
Shape the data
Design the retrieval
Control the grounding
Monitor the system
Evaluate the full pipeline
You’ve moved past the “let’s vectorise our docs” stage.
You’re now thinking like a retrieval architect — with clarity on where things break, and how to build them to last.
And that’s the real unlock.
Because in a world rushing to plug in LLMs, those who master retrieval will quietly run circles around everyone else.
Welcome to the deep end.
Stay dangerous.
I cannot thank you enough! I love your writing style. To the point and perfectly clear. I would love for some code to be included. In any case huge thank you!
Very helpful