

Why Every AI Builder Needs to Understand MCP
The Model Context Protocol is redefining how we build with AI. Here’s what it is, why it matters, and how to use it to build your own modular AI Second Brain.

LLMs are powerful.
But they weren’t designed to operate in real-world environments on their own.
They can generate text.
But they don’t know how to access tools, query APIs, fetch files, or maintain long-term memory—unless you manually wire those systems together.
And that’s the problem.
Every time you want your model to do something useful, you:
Build another wrapper
Hardcode another integration
Stitch another brittle prompt flow
There’s no shared interface between the model and the systems it needs to work with.
This doesn’t scale.
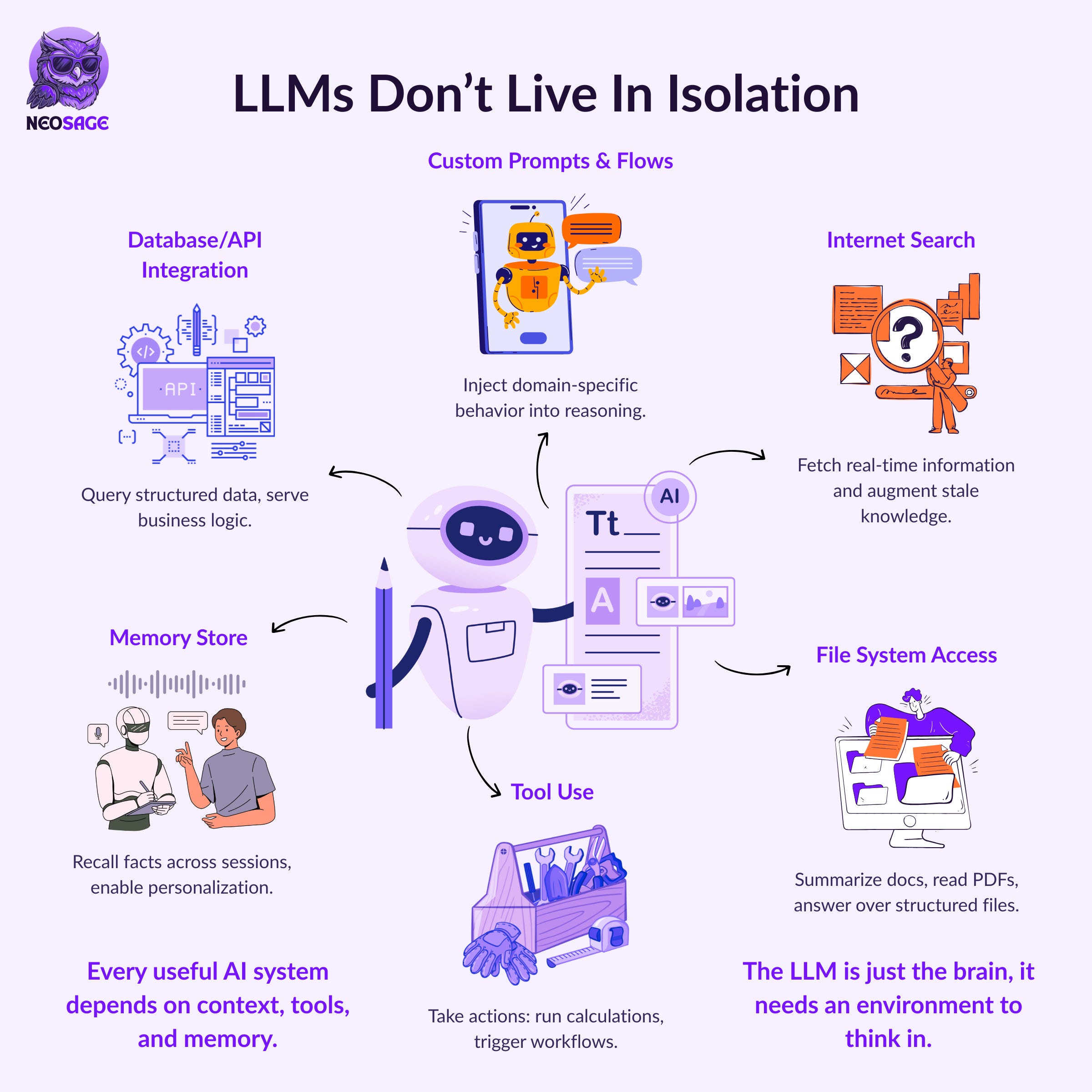
That’s where MCP (Model Context Protocol) comes in.
In this issue, we’ll break down:
What makes today’s LLM integrations fragile and repetitive
How MCP (Model Context Protocol) introduces clean separation between models and tools
How it works under the hood
And how to use it to build a fully modular Second Brain with Claude
Let’s dive in.
The Application Layer Reality
Most LLMs today are built for one thing:
text prediction inside a context window.
That’s not the same as system behavior.
Real applications need more than language—they need structure.
When you step into the application layer, the model is just one piece.
To build a working system, you need to:
Access internal documents and file systems
Pull live information from the web
Query databases and APIs
Chain steps across multiple turns
Maintain memory over time
React to inputs and return usable outputs
But LLMs can’t do any of that out of the box.
Not without external scaffolding.
And right now, that scaffolding is usually handwritten:
You bolt on a wrapper
Patch in a prompt
Hardwire tool logic into your flow
Let’s make this concrete.
Example: A Research Assistant
Say you’re building a Research Assistant with an LLM.
You want it to:
Search internal knowledge bases
Summarise findings from the web
Pull structured insights from APIs
Organise output into clean project notes
But to make that work, you’ll need to:
Write wrappers for file access
Plug into search endpoints
Build prompt flows to chain queries and outputs
Manually inject context between each step
The LLM isn’t acting like a system.
You are, by glueing things together behind the scenes.
It’s not composable.
It’s not scalable.
And it's definitely not reusable.
And up until now?
There was no standard way to do it.
Everyone built their own bridges—fragile, bespoke, duct-taped into existence.
Every new tool meant a new integration.
Every platform shift meant rewriting half your code.
Every update felt like starting from scratch.
The result?
Brittle architectures that break under their own weight.
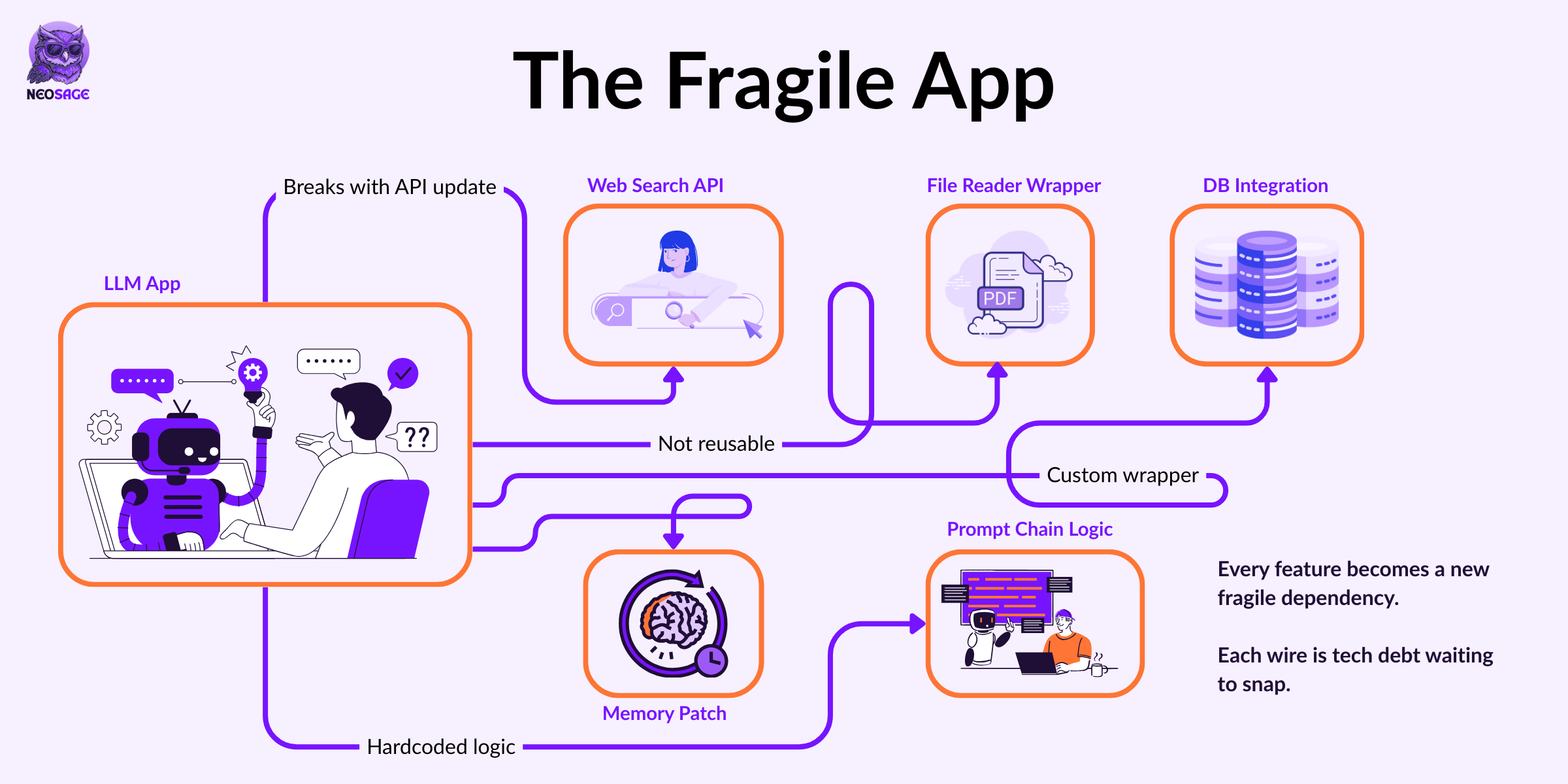
And that’s the hidden bottleneck that stops LLMs from scaling into true modular systems.
It’s the bottleneck that MCP was designed to solve.
The Fragile State of LLM Applications Today
At first, the hacks seem fine.
You hardcode a wrapper here, a prompt flow there.
You scrape together a way to get the model working with your file system, a search API, and maybe a memory loop.
And for a while, it holds.
But then the system grows.
You add a new capability.
A new tool.
A new workflow.
And suddenly, everything feels fragile.
Because every piece is tightly coupled:
Your API logic is baked into your prompts
Your memory patch relies on exact formatting
Your file reader is wired directly into the model context
Nothing is modular.
Everything is handcrafted.
You tweak one thing, and something else breaks.
You try to reuse logic in a new assistant, but the wrappers were written for one use case only.
You upgrade your model, and the entire flow has to be debugged from scratch.
The system doesn’t scale.
It mutates.
And you’re stuck holding it together.
Why This Matters
This isn’t just frustrating.
It’s the core bottleneck behind most LLM systems today.
You’re not failing because the model can’t reason.
You’re failing because there’s no standard interface between your model and the real world.
Up until now, you had two options:
Build everything custom
Or limit what your app could actually do
Neither is sustainable.
Scaling Breaks Everything
Let’s say your Research Assistant is live.
It pulls documents, searches the web, queries APIs—you wired it all up manually.
Now your team wants to expand.
They ask for:
A Sales Assistant that pulls customer data from the same database
A Project Manager bot that uses the same search functionality
A Marketing agent that also pulls docs and formats summaries
Each of these needs:
File system access
Internet search
Access to structured APIs
In a perfect world, you’d just plug them into what you already built.
But that’s not what happens.
You rewrap the same logic again and again:
The Sales bot gets a new DB wrapper
The PM bot gets its own search integration
Each assistant has its own custom prompt chain, tied to a slightly different tool flow
What started as one app using three tools becomes three apps using the same tools—but with three separate integrations each.
M apps × N tools = M×N custom connections
Every line of integration is fragile.
Every wrapper is bespoke.
Every update means rewriting across the stack.
Instead of scaling, you multiply chaos.
The result?
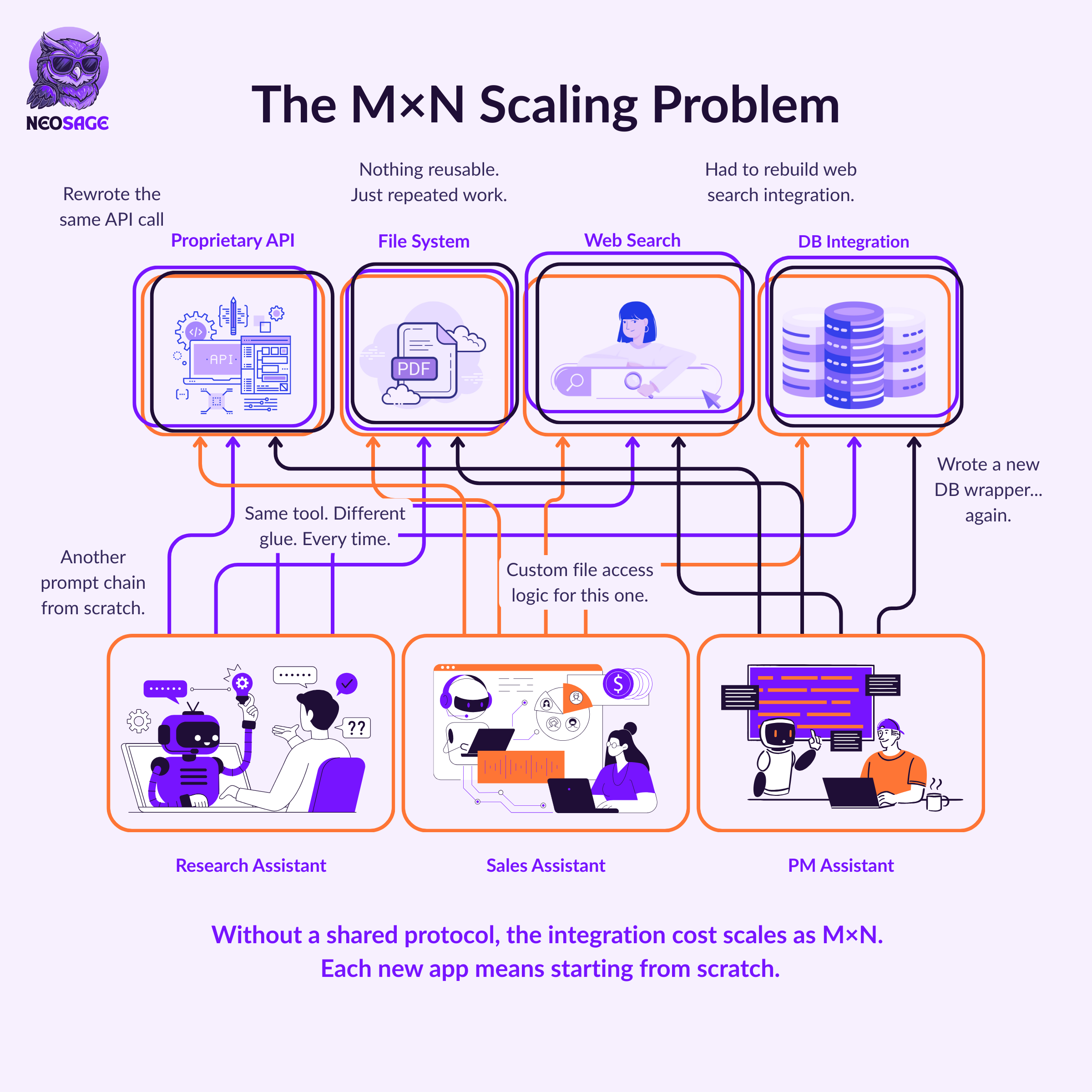
Your simple system has become a house of cards.
This is the point most AI systems start breaking down, not because the model can’t handle the work,
But because the surrounding architecture wasn’t built to scale.
There’s no shared layer.
No reusable interface.
No clean way to connect multiple apps to the same set of capabilities.
Up until now.
MCP: The Missing Infrastructure Layer
If you’ve worked on any non-trivial LLM system, you’ve probably felt it:
The model isn’t the hard part. The integration is.
Same tool. New integration. Every time.
That’s the real cost of building without a standard interface.
MCP (Model Context Protocol) exists to fix this.
It’s an open protocol that defines how models can interact with external capabilities—
like tools, data, prompts, and memory—using structured, discoverable interfaces.
No wrappers.
No one-off glue logic.
No bespoke JSON hacks just to reuse the same capability twice.
With MCP:
You expose a capability once—as a resource, tool, or prompt
Any MCP-compatible model can discover and use it
You stop rewriting integration code across agents, workflows, or frontends
It’s not a framework.
It’s the interface layer that’s been missing from LLM systems.
How MCP Works
Modern LLM systems fail when the model has to know too much about how tools are built.
LLMs aren’t meant to know how tools work.
And tools shouldn’t care what model is calling them.
MCP enforces that separation.
It introduces a simple but powerful structure:
A clean boundary between where the model runs, where protocol logic lives, and where external capabilities are exposed.
The Core Actors: Host, Client, Server
Here’s the basic architecture:
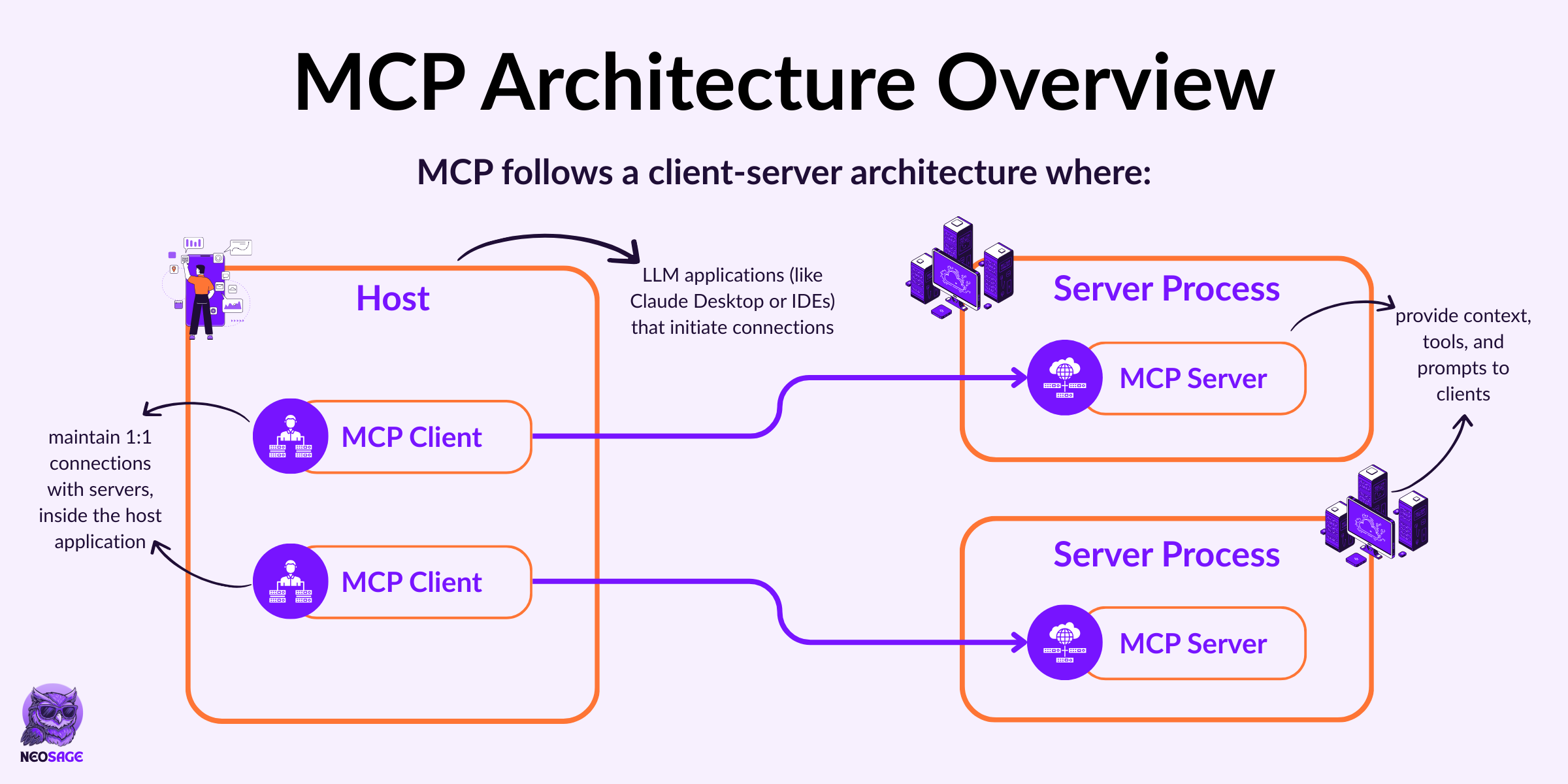
Host
The application running the model—like Claude Desktop, an IDE plugin, or an agent runtime.
It provides the user experience and handles orchestration.Client
A protocol engine that lives inside the host.
It connects to MCP-compatible servers, sends requests, handles responses, and manages the message lifecycle.Server
A standalone process that exposes capabilities—like tools, resources, memory, or prompt templates—via typed interfaces over MCP.
Each actor has a single responsibility:
✅ Hosts don’t need to know how tools are implemented
✅ Servers don’t need to know how their output is displayed
✅ Clients translate between the two reliably and predictably
They speak the same protocol: JSON-RPC over a flexible transport layer.
This structure is what makes MCP scalable:
One model. Many servers. Clean boundaries. No shared assumptions.
How They Communicate: The Message Flow
Every interaction between an MCP Client and Server follows the same protocol:
Structured, typed messages using JSON-RPC 2.0.
Core Message Types
MCP supports four core message types:
Request — Sent by the client to ask the server to perform an action
Response — Sent by the server when a request succeeds, returning a result
Error — Sent by the server when a request fails
Includes acode, amessage, and optionaldata(for structured debugging)Notification — One-way messages that don’t expect a response
(e.g., server announces a tool list update)
These messages are typed, versioned, and schema-validatable, making them consistent and extensible across tools and clients.
The Lifecycle
An MCP session follows a predictable sequence:
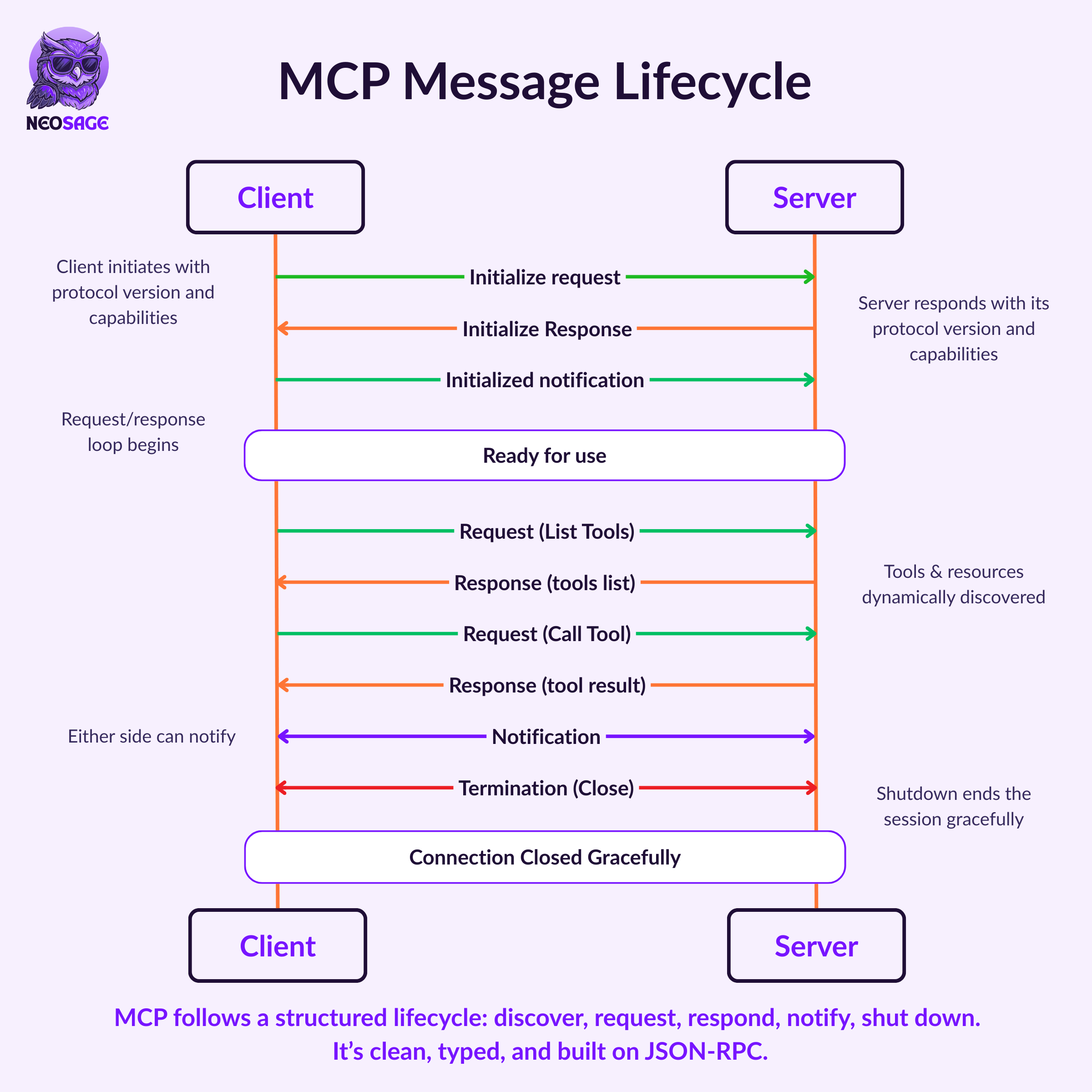
1. Initialization
The client sends an
initializerequest, declaring its protocol version and capabilitiesThe server responds with its own capabilities
The client confirms readiness with an
initializednotification
2. Communication
The client issues typed requests to the server (like
callTool,readResource)The server replies with results or structured errors
Either side can send notifications to announce updates or state changes
3. Shutdown
Either the client or the server can initiate a clean shutdown via
shutdownandexit
All messages are logged and type-checked, making the protocol reliable for large-scale applications and easy to debug.
How Messages Move: The Transport Layer
While the message structure is always JSON-RPC, MCP supports flexible transport options:
stdio — Fast, local, ideal for small or embedded tools
http — Stateless, commonly used for hosted deployments
sse (Server-Sent Events) — Persistent streams for long-lived processes
Custom transports — You can define your own, as long as JSON-RPC is preserved
Whatever the transport, the message contract stays the same.
That’s what makes MCP modular—infrastructure can change, but the interface doesn’t.
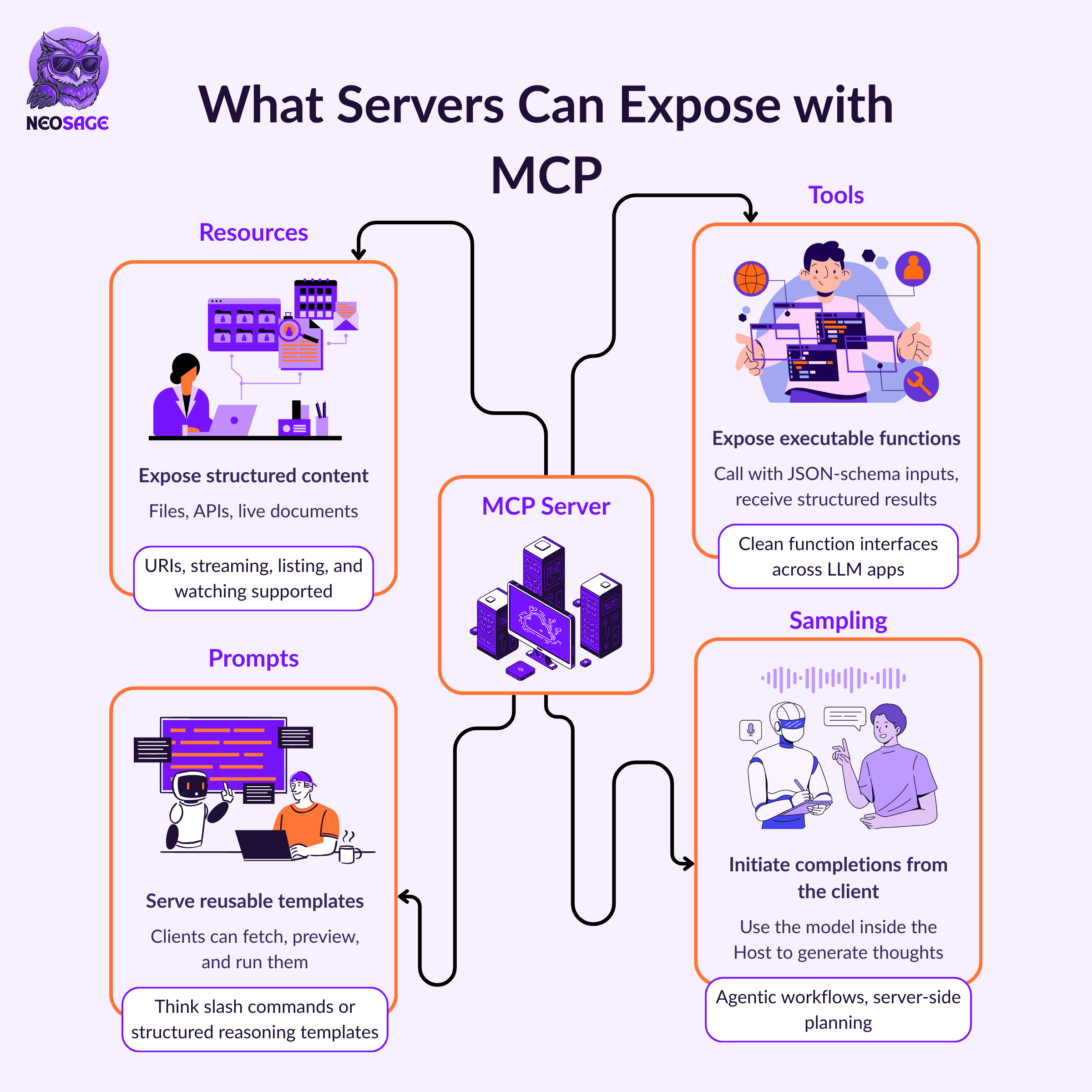
What Servers Can Expose
Every MCP server can expose one or more structured capabilities to the client.
These are called primitives, and each follows a well-defined schema and discovery flow.
Resources
Expose structured or dynamic content—like file systems, APIs, or generated documents.
Clients can:
List available resources
Read or stream their content
Subscribe to updates via notifications
Prompts
Serve reusable, parameterised prompt templates.
Clients can:
List available prompts
Preview how they behave
Invoke them with specific input
This allows you to standardise reasoning steps, formatting, or task flows.
Tools
Expose executable actions—each defined with a JSON schema for input and output.
Clients can:
Discover tool metadata
Call tools with structured arguments
Receive typed, predictable results
This makes functions callable like APIs—without custom glue.
Sampling
Let the server initiate model completions using the host’s LLM.
This is used when the server needs to ask the model a question, for planning, intermediate reasoning, or delegated generation.
It supports:
Structured prompts sent from the server
Completions returned from the client-side LLM
Use in multi-agent chains or feedback loops
Together, these primitives allow servers to offer rich, typed capabilities—
and allow clients to discover, use, and compose them without writing bespoke logic per app.
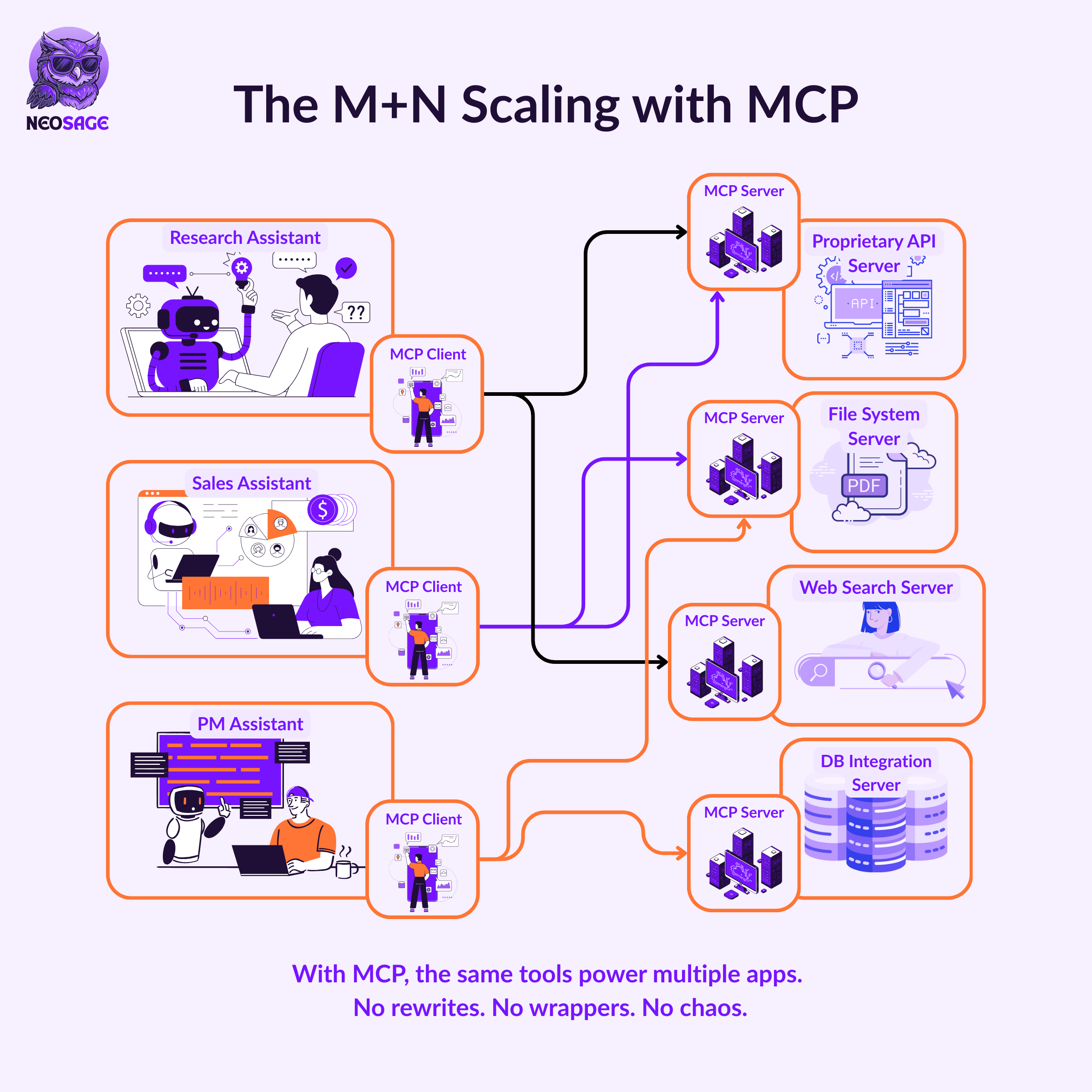
From M×N to Modularity
Earlier, we saw what breaks:
M apps × N tools = M×N custom integrations
Every new assistant.
Every shared capability.
A new wrapper. A new prompt chain. A new point of failure.
Now let’s look at what happens with MCP.
Say you’re building the same three assistants:
A Research Assistant that needs to access internal documents
A Sales Assistant that needs to query customer data via API
A Project Manager that needs to fetch live market insights from the web
Each assistant depends on:
A document store
A structured internal API
A search interface
With MCP, those capabilities are exposed once, as servers.
Each tool or resource is packaged as an MCP server, with a typed, discoverable interface:
A Filesystem server
A Web Search server
An API server
Each assistant connects to those servers through a dedicated MCP client.
Clients maintain a 1:1 connection to each server
The host (e.g. Claude Desktop) manages these connections per server
Assistants issue typed requests through the appropriate client
Servers respond with structured results—no custom glue required
There’s no duplicated wiring.
No per-app integration logic.
No more M×N explosion.
You don’t wire logic into every app.
You expose capabilities—and let apps connect to them.
Why It Matters
This is how you solve the real scaling bottleneck:
Capabilities are written once
Interfaces are reused across assistants
Behavior is separated from infrastructure
With MCP:
Models use tools they weren’t handcoded for
Tools don’t depend on prompts or app logic
Assistants become orchestrators—not wrappers
You stop stitching things together.
You start composing real systems.
Building Your Second Brain with Claude and MCP
Understanding MCP is one thing.
Building with it is where the design comes alive.
And there’s no better place to start than setting up a modular Second Brain—
an AI system that can search, retrieve, reason, and grow without glue code or prompt hacks.
The Setup: Claude + MCP Servers
At the heart of this setup:
Claude Desktop acts as the host and client
(Already supports MCP natively)MCP Servers are lightweight programs you run locally
(Each one exposes tools, resources, prompts, or memory as structured capabilities)
When Claude connects to these servers, it can use them dynamically—
No brittle wrappers, no hardwired integrations.
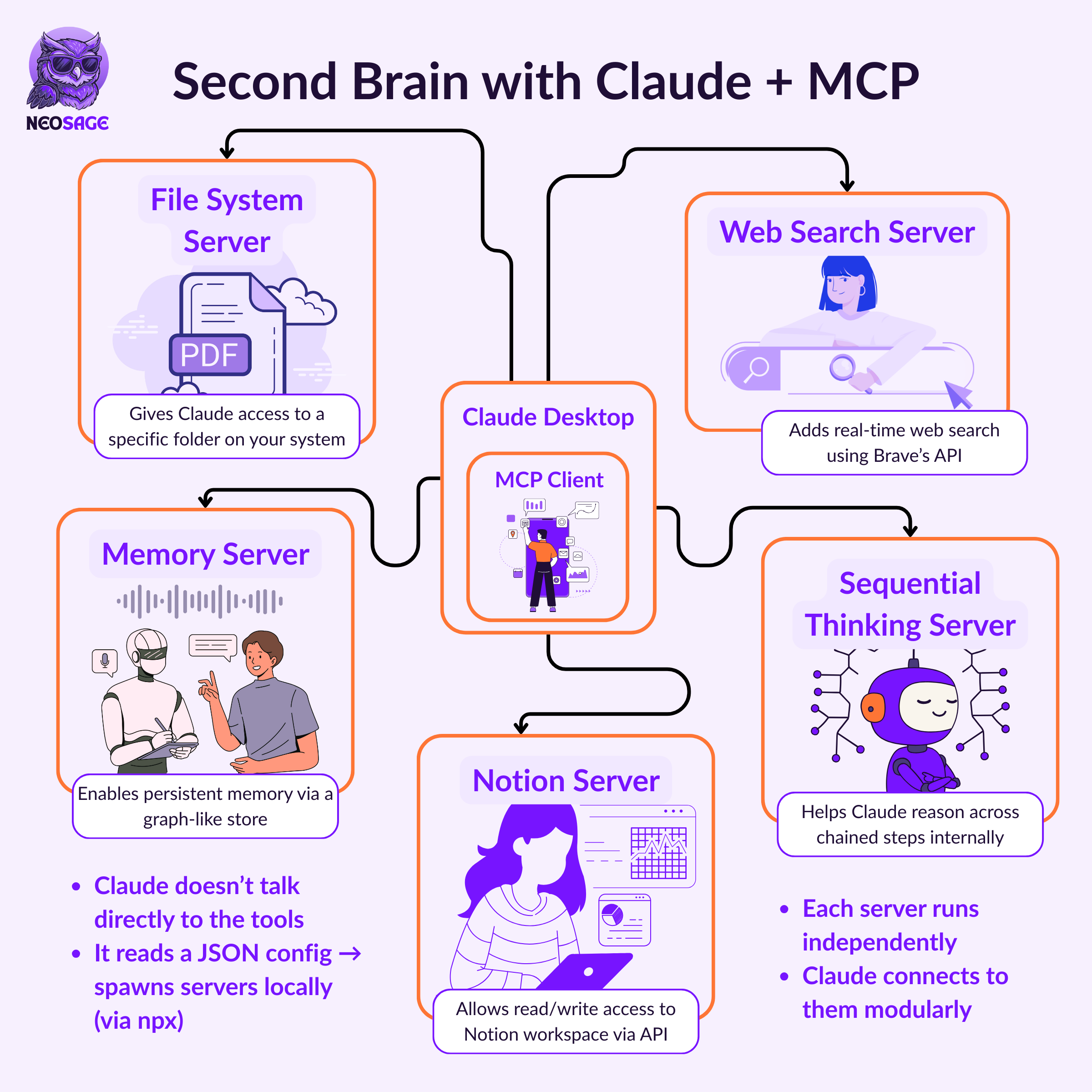
Minimal Second Brain Stack
✅ Filesystem Server
Enables Claude to read and write files from a designated directory
Secure, modular file access✅ Web Search Server
Enables real-time internet search using Brave’s API
Private, dynamic querying✅ Memory Server
Provides persistent memory across sessions using a graph-backed store
Recall facts, retain context✅ Sequential Thinking Server
Enables multi-step reasoning and internal thought chaining
Execute multi-turn tasks naturally✅ Notion Server
Enables interaction with your Notion workspace
Fetch, update, and manage pages + databases
Quick How-To: Setting it Up
Install Claude Desktop
(If you haven’t already)Edit the Config
InsideSettings → Developer → Edit ConfigPaste the following:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/<youruser>/ClaudeFileSystem"
]
},
"brave-search": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-brave-search"
],
"env": {
"BRAVE_API_KEY": "<your-api-key>"
}
},
"memory": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-memory"
]
},
"sequential-thinking": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-sequential-thinking"
]
},
"notion": {
"command": "npx",
"args": ["-y", "@suekou/mcp-notion-server"],
"env": {
"NOTION_API_TOKEN": "<your-token>"
}
}
}
}✅ This tells Claude exactly how to launch and manage each server.
(Reminder: replace <youruser>, <your-api-key>, and <your-token> with your real values.)
Restart Claude Desktop
It will automatically detect and connect to the servers.
✅ Done.
You now have a modular Second Brain running locally.
Why This Setup Matters
Each server adds one clean capability—
without coupling, without rewriting, without fragile dependencies.
You can:
Add tools by spinning up new servers
Swap implementations without changing app logic
Extend workflows without rebuilding everything from scratch
Today, it’s a Research Assistant.
Tomorrow, it’s a Knowledge OS.
The day after, it’s a fully modular agentic workspace.
All of it powered by shared infrastructure—not hardcoded glue.
From Brittle Hacks to Modular Systems
Building AI systems isn’t about throwing prompts at a model.
It’s about creating structure that scales.
The old way?
Manual wrappers
Prompt spaghetti
One-off tool integrations
Every new capability came with a new risk.
MCP changes that.
It’s not just a way to connect LLMs to tools.
It’s a protocol layer—
A boundary between models and the world.
Hosts focus on orchestration
Clients speak the protocol
Servers expose typed, reusable capabilities
Whether you’re setting up a Second Brain or architecting multi-agent ecosystems—
MCP gives you the system layer that LLMs were always missing.
And in the future of AI systems?
Modularity isn’t a preference. It’s the requirement.
The best explanation I ever got. Thank you.
I love your explanation