

Your agent re-reads the same context every step, at 10x the price
Four ways the field is attacking the context bottleneck this week, where the coding-agent fight is really moving, and why "AI is replacing engineers" doesn't survive the data.

You can wire up the best model on the market and still ship an agent that's slow and quietly expensive. Past a certain point, the thing that decides which way it goes isn't the model at all, it's how you handle the context it carries, the pile of tokens that keeps growing as it works. For anything that runs long, an agent working for hours, a model reasoning over a huge document, that has become the real engineering problem.
The specific pressure point is the KV cache. As a model reads your prompt, it builds and stores an internal representation of every token so it doesn't have to recompute that work on the next step, and that store, the cache, grows right alongside the context. Run an agent for forty turns over a long transcript and a large share of its time and cost goes into just carrying that cache forward. So once contexts get big, managing the cache well starts to matter more than which model you picked.
That's the thread this week. An unusual amount of the sharpest work was aimed straight at that one problem, from four different directions, and I've lined them up. After that: where the coding-agent race is quietly moving, and why "AI is replacing engineers" doesn't survive contact with the data.
Your agent's real cost is cache misses, not tokens
What makes the cache worth obsessing over is a pricing quirk. When a provider has already processed part of your prompt, it can reuse that work on later steps instead of redoing it, and it charges you far less for those reused tokens. On Claude Sonnet, the Manus team measured reused tokens at $0.30 per million against $3.00 for fresh ones, ten times cheaper. And since an agent's context keeps growing while its actual replies stay short (Manus saw roughly a hundred input tokens for every one it generated), that cache is where most of the money goes. So the lever isn't how many tokens you send. It's how many of them the provider can reuse instead of recomputing.
Here's the part that catches people. The usual ways teams try to save money quietly defeat this. Prune an old message, drop a memory, reorder your tool list, and you've changed something near the top of the prompt, which forces everything below it to be recomputed from scratch. Your token count goes down and your bill goes up.
TokenPilot (arXiv:2606.17016) is one way to manage context with that in mind. Two ideas. First, keep the top of the prompt stable so it stays reusable: the parts that change from run to run, timestamps, file paths, get swapped for fixed placeholders, and noisy tool outputs get trimmed as they arrive, with a way to fetch the full original back if a later step needs it. Second, be careful about removing things: a finished sub-task isn't dropped the moment it's done, it's kept while later steps might still need it, and when things are removed they go all at once rather than a little each turn, because every removal changes the prompt and costs you the reuse you were banking on.
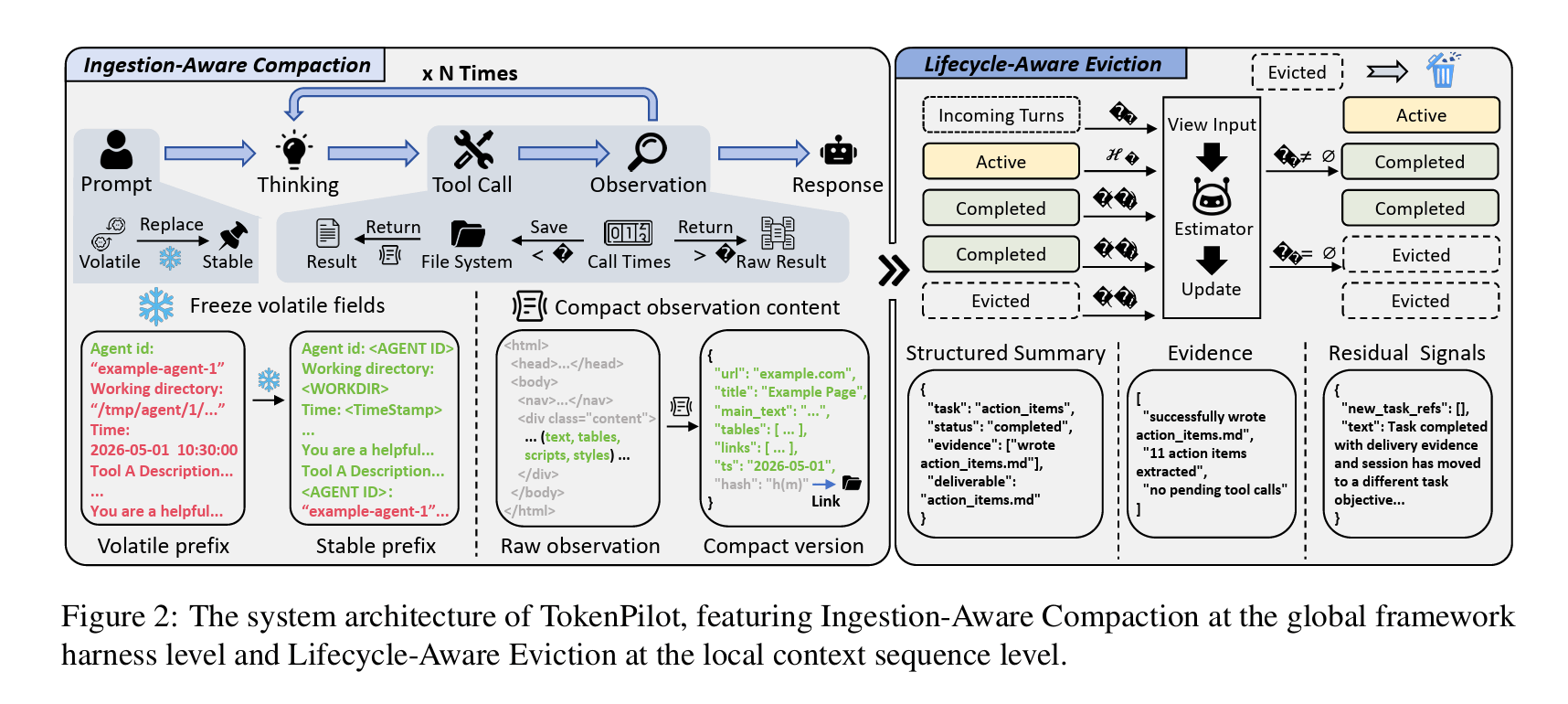
Their clearest result is a good gut-check. When they switched on their method, the number of reused tokens actually went up and the bill still went down, because the change converted a chunk of expensive recomputed tokens, the cache misses, into cheap reused ones. That's the reframe worth keeping: total token count is a vanity number; the one that tracks your bill is how much gets recomputed. They report cost cuts of 56 to 87 percent on their agent benchmarks, the high end on long sessions where a stable prompt pays off across many tasks, with quality holding.
One nuance, because it's where the real judgment is. Keeping the cache happy is a genuine constraint, but it can't be the only one. The Manus team make this point well: they refuse to hobble the agent just to protect the cache. They keep all the tool definitions in place and simply hide the ones that aren't available at a given moment, instead of adding and removing tools mid-run and blowing the cache. TokenPilot's recovery tool is the same instinct: trim hard, but keep a way back, so the savings never quietly cost you a correct answer. The concrete move for you is small: before you reach for compression, measure how much of your prompt is actually being reused, and find what's breaking it. Often the cheapest win is just getting the top of your prompt to stop changing.
⭐️ The open-source repo worth checking out this week
An agent doesn't just answer, it acts, with real permissions: it sends the email, moves the money, deletes the record. So when an agent goes wrong, it doesn't say something wrong, it does something wrong. And there are many ways to push it there: a malicious instruction hidden in a web page or a tool's output, a request that talks it past its remit, a tool used in a way you never intended. What makes it hard to catch is that the damaging action almost always looks normal on its own, resetting a password, sending a file. It's only wrong in light of the job the agent was actually given, which is exactly what a filter scanning for "bad" content can't see.
Catching it takes three things:
Judge intent, not keywords. Decide whether an action fits the agent's actual remit, not whether the text around it looks malicious.
Gate before, don't log after. Check the action in the moment between deciding and doing, so you can stop it, not just report it once it's done.
Harden the checker. The check is itself run by a model, so an attacker will try to manipulate it too. It has to be sealed off, no tools, no internet, or it just becomes the next way in.
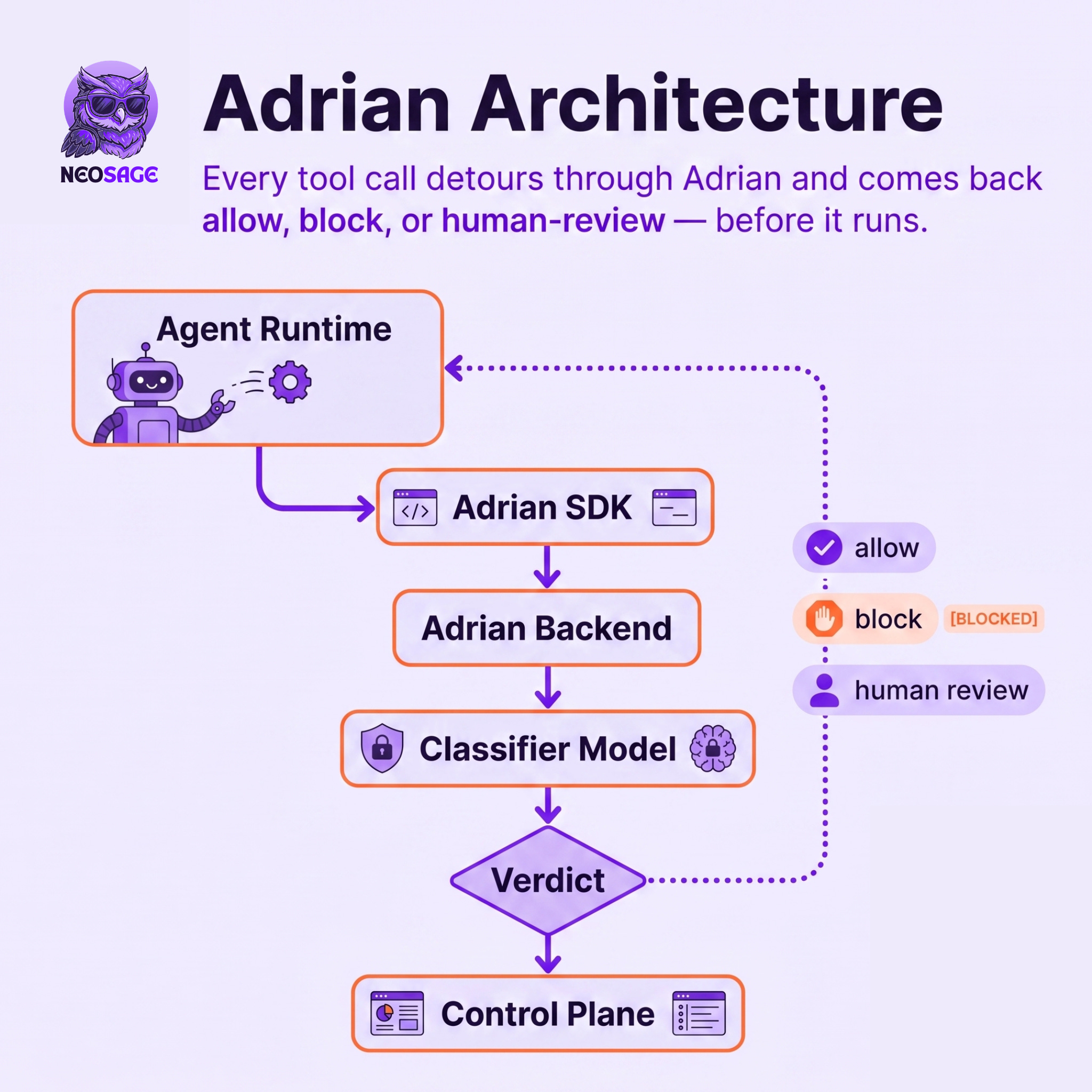
Adrian, from Secure Agentics, is an open-source toolkit built around exactly those three. You wrap an existing agent in two lines of code; it reads the agent's reasoning, weighs each tool call against the remit you set, and blocks anything out of bounds before it runs, with its own checker sealed off so it can't be turned against you. It works with LangChain, LangGraph, and the OpenAI Agents SDK, in Python or TypeScript, with Claude Code support coming soon. Apache 2.0, free.
⭐ Star the repo
💬 Join the Discord
📦 Install: pip install adrian-sdk
The model can read a compressed context, if you train it to
That last approach keeps your text intact and gets clever about the cache. This one is more radical: it shrinks the text itself into something the model reads directly.
The problem here is memory. As a model works, it has to hold the whole context in memory, and that grows with every token. Push the context into the hundreds of thousands of tokens and you hit a hard wall, you run out of GPU memory. There's a softer failure too: models get noticeably worse at using information buried in the middle of a very long context. The usual fixes try to shrink the stored context after the fact, and they tend to either hurt quality or run too slow to be practical.
Latent Context Language Models (arXiv:2606.09659) take a different route: train the model to read a compressed context. A small encoder reads the input in chunks and squeezes each chunk down to a single dense vector, a "soft token" that stands in for, say, sixteen real tokens. The main model is trained from the start to treat those soft tokens as if they were ordinary words. So instead of reading a million tokens, it reads a sixteenth as many, and its memory footprint falls to match.
The obvious worry is fidelity, you cannot recover an exact name or number from a vector that averaged sixteen tokens together. Their answer is a two-tier setup. The compressed view is for cheaply scanning the whole context and finding roughly where the answer lives; then an EXPAND tool pulls back the original, uncompressed text of the one chunk that matters, so the model can read that part word for word. Fuzzy and cheap to skim, exact when it counts.
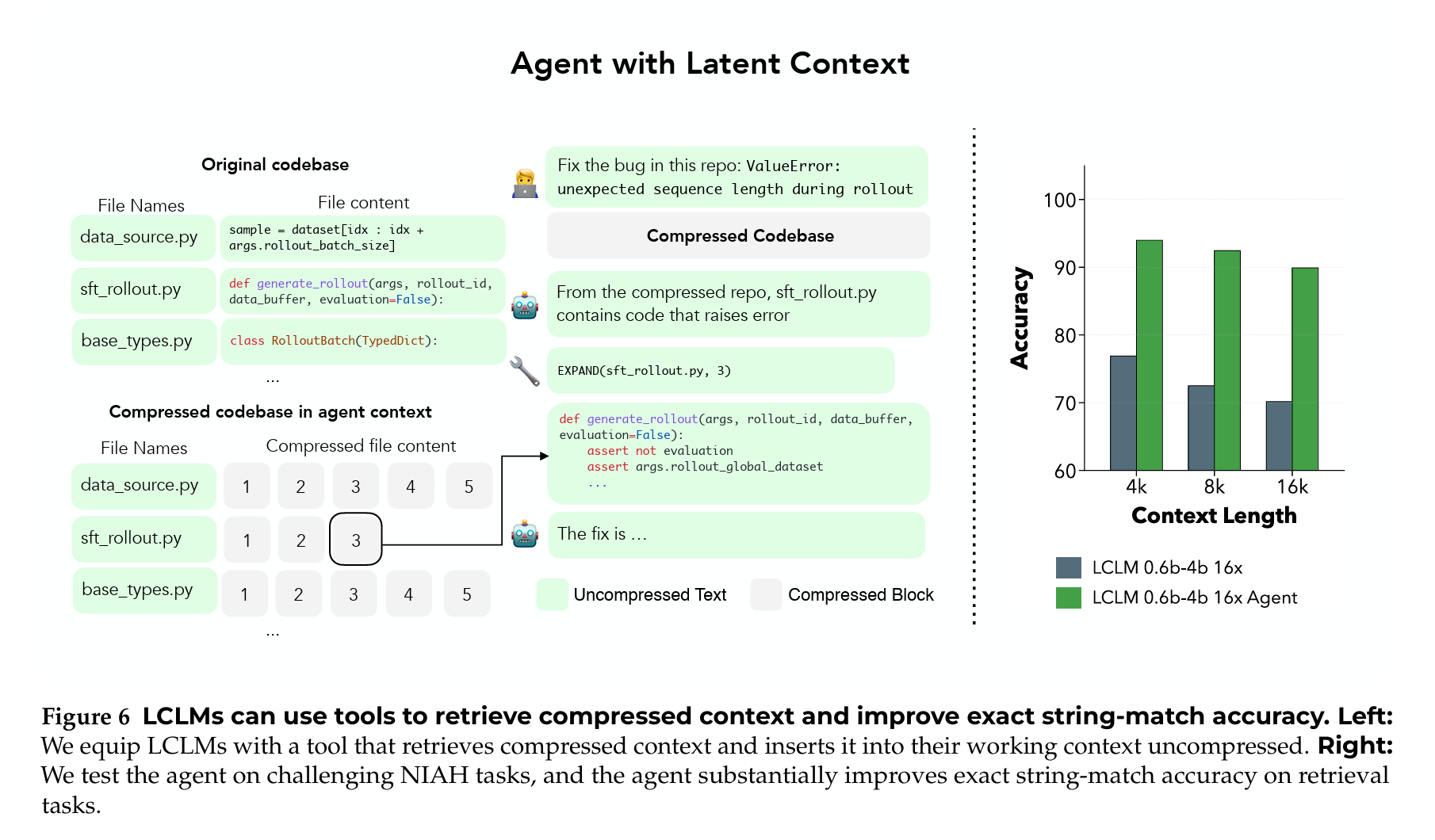
The mental model is the part worth keeping: context doesn't have to be stored as raw text. It can be stored as a learned summary the model was specifically taught to read, with a button to un-summarize. The cost, though, lands somewhere awkward. You cannot add this to a model you already run. It requires continued pre-training on an enormous amount of data to teach the model to read latents, which means a real training bill and a commitment to one specific encoder-and-model pairing. So it earns its keep when your contexts are genuinely huge, the kind where you would otherwise run out of memory, and it isn't worth the trouble when your context already fits comfortably.
Sparse attention, done so it actually speeds up the GPU
Underneath the memory problem is the attention math itself. Attention works by having every token in the context compare itself against every other token, so the total work grows with the square of the context length. At a few thousand tokens that's nothing. At a million, it's a wall you hit before you even start worrying about the cache.
MiniMax Sparse Attention (arXiv:2606.13392) starts from something most of us already believe: a given token doesn't really need to look at all million others, it cares about a handful of relevant regions. So MSA chops the past into fixed blocks, uses a small, cheap index to score which blocks matter for the current token, keeps only the top sixteen, and runs full attention over just those. The work per token is then fixed, no matter how long the context grows.
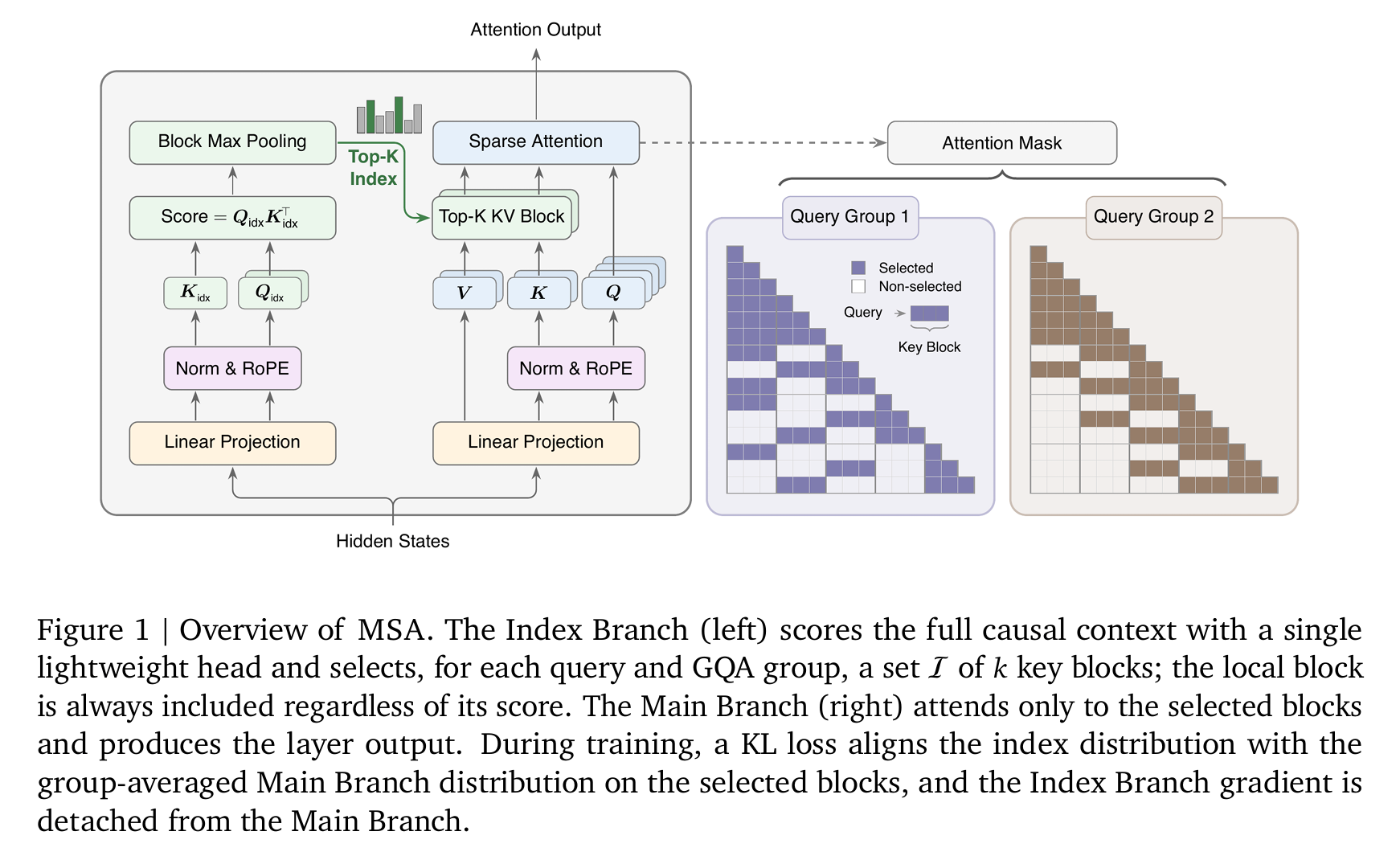
Two things make this more than a neat idea. The block-scoring index isn't a hand-written rule, it's trained to predict where the model's real attention would have looked, so it learns to retrieve the right regions on its own. And the team is refreshingly honest about the catch most sparse-attention work skips over: cutting the math doesn't automatically make a GPU faster, because GPUs are built for dense, regular work, and a naive "go fetch these scattered blocks" pattern stalls them. Most of the paper is the custom GPU code that turns the theoretical savings into real ones. With it, they report roughly a 28x cut in attention compute at a million tokens, and real speedups (about 14x to fill the context, 8x to generate) at quality close to ordinary dense attention.
The honest scope: this is a choice you make when you build or convert a model, and it takes hundreds of billions of tokens of training, so it isn't something you switch on for a model you already have, and the GPU code is hardware-specific. If you don't train your own models, read this as where long-context inference is heading rather than a change you make this week. But it's the week's clearest sign that the long-context problem is being pushed all the way down into the attention kernel.
OpenAI's next coding-agent bet is infrastructure, not a model
Step out of the papers for a moment. OpenAI is buying Ona, the company that used to be Gitpod, and folding it into Codex (announcement). Ona's product is secure, persistent cloud development environments, a place an agent can keep working for hours after you've closed your laptop, running inside the customer's own cloud with their credentials and guardrails around it. OpenAI says Codex is now past five million weekly users, up roughly 400% this year.
The signal is the thing to take. The next gain for coding agents isn't a smarter model, it's a durable, governed place for the agent to actually run. A long-running agent needs a persistent sandbox, managed credentials, and a cap on how much damage it can do, so it can't delete the wrong files or quietly burn a fortune in tokens. That's infrastructure, and the big labs are now buying and building it: Anthropic shipped self-hosted sandboxes for Claude Code back in May, and OpenAI is answering with an acquisition. The deal hasn't closed yet, so this is a direction, not something you can pick up today. But the direction is the story, as raw model quality levels off, the advantage is moving to the environment the agent lives in.
One thing to ship this week
Before you optimize context cost, measure the right number. Pull your agent's token bill and split it into cache hits and cache misses, the misses are the part you actually pay for, often around 10x the price of a hit. Then look at what's invalidating your prefix: a timestamp near the top of the prompt, a tool list that reorders between runs, a memory eviction mid-session. Half the time the cheapest win isn't compressing anything, it's stabilizing the prefix so the cache stops getting thrown away. Total tokens is the number you can see; cache-misses are the number you pay for, so measure that one first.

Overrated this week: the idea that AI is replacing engineers
Every layoff this year seems to arrive with an AI explanation attached. The numbers don't back the story. When New York added a box to its layoff filings letting companies attribute cuts to AI, almost none did, out of 160-plus filings in the first year, essentially zero checked it. Yet a survey found a majority of managers admitting they had blamed AI for layoffs anyway, because it plays better with stakeholders than the real reason. The replacement narrative is doing a lot of work that AI itself isn't.
There's a useful way to see why. Writing code was never the hard part of engineering, and it was never most of the job. The work is deciding what to build and why, designing how the pieces fit, and then the long tail of making it real, testing it, integrating it, securing it, and owning it when it pages you at 2am. AI has genuinely sped up the writing. It has barely touched the rest, and the rest is where engineering actually lives. An NBER study put numbers on the gap: with coding agents, developers produced something like eight times more code but only about thirty percent more actual releases. The typing got cheap; shipping didn't. A separate study of real-world agent use found only about 44 percent of AI-written code even survives to a human commit, with developers reaching for these agents to understand existing code at least as often as to write new.
The enterprise is hitting the same wall, just with bigger budgets. 2025 was crowned the year of AI agents, Nvidia's Jensen Huang pitched a multi-trillion-dollar future where your IT team becomes the HR department for a fleet of them, and then the projects met production. Gartner now expects more than 40 percent of agentic-AI projects to be scrapped by the end of 2027, and the reason it gives isn't weak models, it's cost, fuzzy value, and missing controls. A widely-cited MIT survey of enterprise GenAI found around 95 percent of pilots showing no measurable return, and put the blame on the integration gap, not the model. What keeps tripping everyone is the unglamorous part, the systems thinking: getting an agent to hold up inside real workflows, real data, and real failure modes, and standing behind what it produces. That was always the hard part of the job, and it's still yours.
That's the week. The thread under it: the model stopped being the expensive part. For long-horizon, big-context systems the cost and the bottleneck are the context itself, and the field is attacking it from four directions at once, keep the junk out, engineer the cache, compress the tokens, change the attention. Whichever fits your stack, the first move is the same, find out what your context is actually costing you.
If one of these hit something you're wrestling with, reply and tell me what you're building. I read every one.
Stay dangerous,
Shivani