

How GPTs Learn to Be Helpful
The missing step between raw model and assistant—and why it matters for builders

Introduction
This issue is a continuation of Part 1.
If you haven’t read it yet, start here

If you’ve ever wondered how ChatGPT became ChatGPT—the assistant that can explain quantum mechanics and gracefully decline weird requests—the answer lies in what happens after pertaining.
The raw model underneath is powerful, yes.
But it’s not polite. Not helpful. Not safe.
It doesn’t know when to say “I don’t know” or how to actually assist.
That’s because pretraining gives you a brain, a lossy internet simulator trained to predict the next token.
Post-training is what gives it a personality. A purpose. A grip on behaviour.
This issue dives into the second stage of model development:
How supervised fine-tuning teaches helpfulness
How reinforcement learning reshapes behaviour
Why hallucinations still happen—and what that reveals
And how these layers set the stage for building AI, you can actually use
If Issue 1 was about how GPTs are born,
This one is about how they grow up.
Post-Training

Supervised Fine-Tuning (SFT)
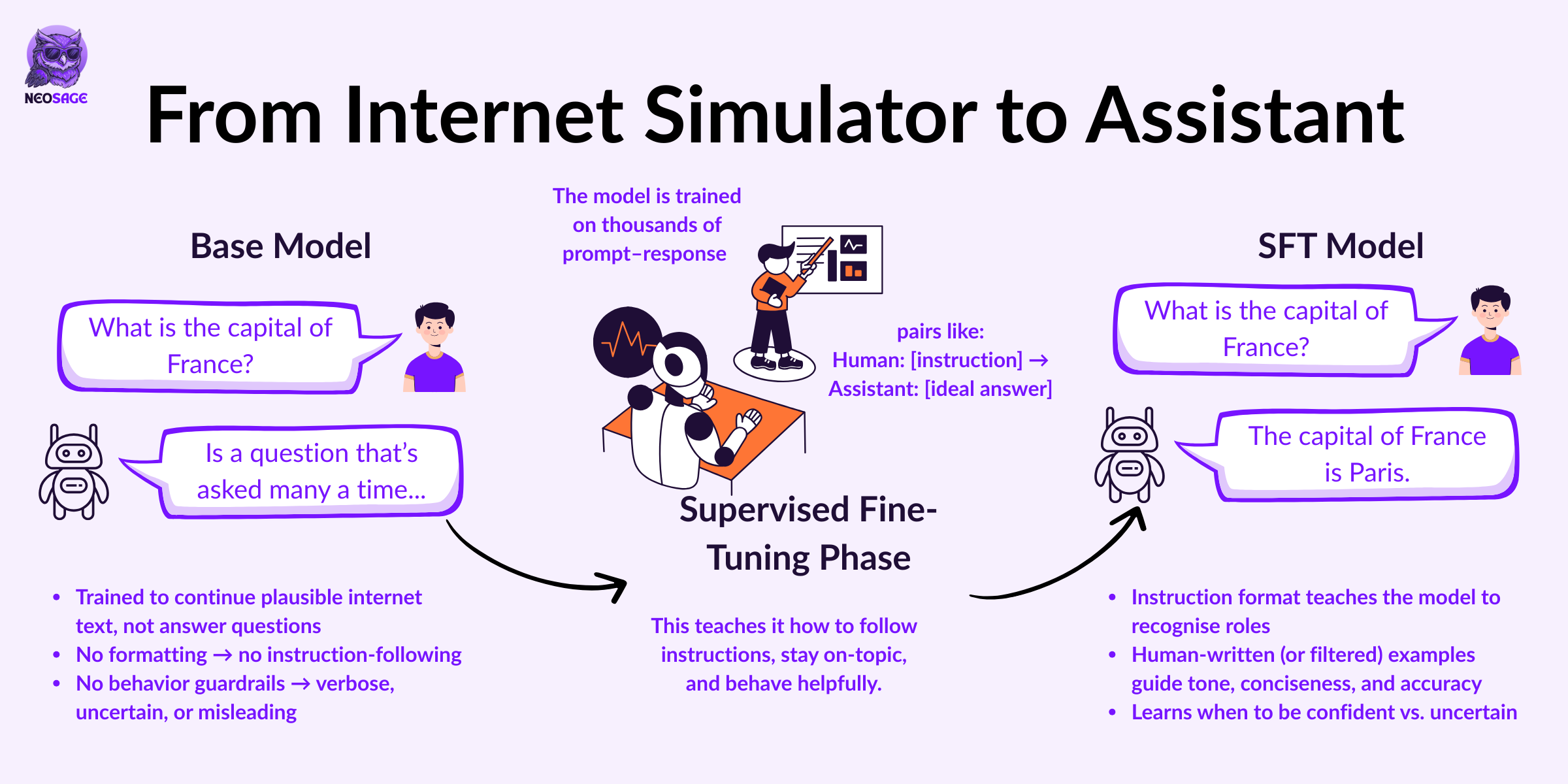
From Internet Simulator to Instruction-Following Assistant
When people interact with ChatGPT, they’re often surprised by how helpful, conversational—even human—it feels. But that behaviour isn’t a natural byproduct of pretraining.
It’s taught after the fact.
So what is Supervised Fine-Tuning (SFT), really?
Let’s revisit the mental model.
The base model is just an internet simulator—a system trained to predict the next token across trillions of examples from web pages, books, forums, and Wikipedia.
It has raw language ability, but no sense of how to be useful.
It doesn’t know when to say “I don’t know,” how to follow instructions, or even what it means to answer a question.
It’s a brain with no behavior.
SFT is the first step in post-training, where we take that raw capability and teach it how to act like an assistant.
It’s trained on thousands (sometimes millions) of human-written conversations, structured like this:
Human: [Instruction or question]
Assistant: [Ideal response]This is where the model learns to:
Follow instructions
Be helpful and polite
Refuse unsafe requests
Admit uncertainty
Show reasoning steps
Without this step, the model would just remix plausible-sounding text. It wouldn't behave.
Where does this dataset come from?
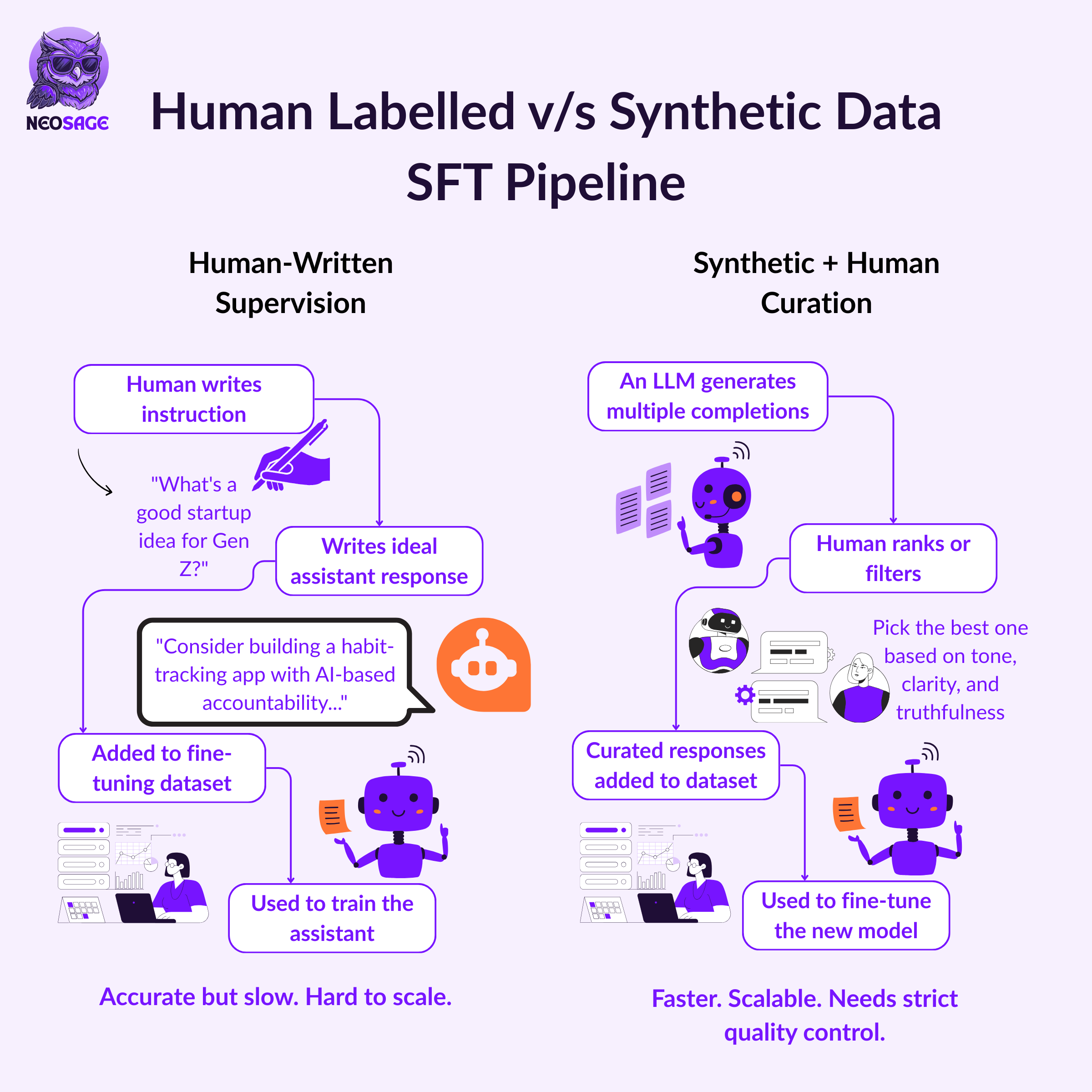
In the early days of supervised fine-tuning, humans wrote everything from scratch.
Labellers followed detailed guidelines on how to be helpful, truthful, and non-biased, often working from instruction manuals hundreds of pages long. They would:
Take prompts like “What are some startup ideas for Gen Z?”
Write out the ideal assistant response, word for word
Repeat this process across thousands of diverse scenarios
While this gave us high-quality data, it was slow, expensive, and hard to scale.
As models improved, a smarter approach emerged:
Instead of writing everything from scratch, we generated responses using a strong model (like GPT-4) and had humans review and filter them.
This process generated synthetic SFT data:
A powerful model creates multiple responses
Humans rank or pick the best ones
Only top completions are added to the training set for smaller models
Synthetic SFT is faster, cheaper, and scalable, as long as quality is controlled.
Without careful monitoring, the assistant could start imitating the bad habits of the model that generated its data.
Thus, synthetic SFT still requires:
Strong evaluation filters
Spot checks for hallucinations and unsafe content
Clear labelling instructions to preserve alignment
It’s not fully automated—it’s just a more efficient way to scale human preferences into usable training data.
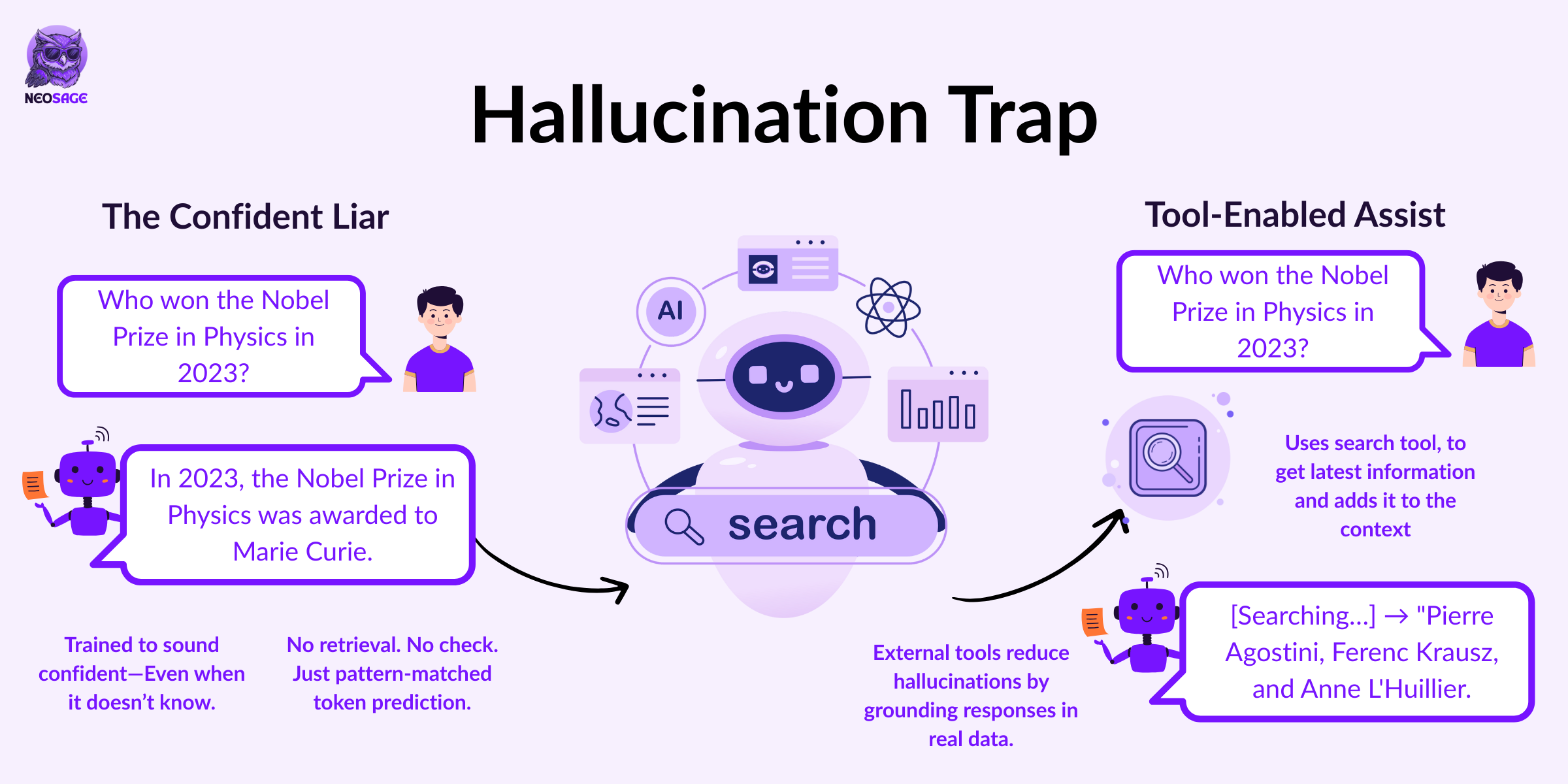
Why do hallucinations still happen?
Supervised fine-tuning teaches models to behave like assistants, follow instructions, sound fluent, be clear and confident.
But here’s the catch:
The model isn’t verifying facts. It’s still just predicting the next token.
So when you ask:
“Who won the Nobel Prize in Physics in 2023?”
It doesn’t look it up.
It searches its training patterns for what might come next—and if it hasn’t seen that fact clearly and repeatedly, it guesses.
And it does so confidently.
Why? Because SFT trains on well-structured, assertive responses.
The model learns not just what to say, but how to say it.
So even when it doesn’t know, it defaults to the tone it was rewarded for:
Fluent. Certain. Complete.
That’s what makes hallucinations dangerous.
They don’t sound unsure—they sound right, even when they’re not.
So, how do we reduce hallucinations?
Better SFT data
→ More factual, grounded, high-quality examples reduce the need to guess.Refusal training
→ Teach the model to say “I don’t know” or “I can’t answer that” through labelled examples. Without them, it assumes confidence is always rewarded.External tools
→ Let the model call a search engine or calculator. If it doesn’t know, it can reach instead of fabricate.
Because the real problem isn’t just a lack of facts.
It’s that the model’s been trained to act like it knows, even when it doesn’t.
And if you want the truth, that behaviour has to be retrained or redirected to something more reliable.
What about self-awareness?
Here’s a fun surprise:
LLMs don’t actually know who they are.
Ask a base model, “What model are you?”
Unless it’s seen that exact phrasing during training, it has no reason to say,
“I’m ChatGPT, based on GPT-4.”
Why?
Because there’s no internal identity.
The model’s not reflecting on its architecture—it’s just predicting the next likely token.
To make it sound self-aware, you have to train or tell it to act that way.
Two ways to do that:
Supervised Fine-Tuning
Include Q&A like:Human: What model are you? Assistant: I am ChatGPT, trained by OpenAI.→ The model learns this identity as a pattern.
System Prompts
Inject context like:“You are ChatGPT, based on GPT-4.”→ Shapes behaviour at runtime without retraining.
These two techniques reflect two kinds of memory:
Parameter memory → baked into the model weights
Context memory → fed dynamically via the prompt
Only one of them, context memory, can you change post-deployment.
So, when a model “knows” who it is
It’s not awareness. It’s pattern repetition.
Why LLMs Struggle with Math (and Counting)

This is where the “token predictor” mental model hits its limit.
LLMs don’t solve problems.
They generate text that looks like a solution, one token at a time.
So when you ask:
Emily buys 3 apples and 2 oranges. Each orange costs $2. The total is $13. What’s the cost of the apples?
You want:
2 oranges = $4 → 13 – 4 = 9 → 9 ÷ 3 = $3 each.
But unless it’s seen that exact reasoning pattern before, it might:
Jump to a guess like “$9”
Mix up the logic midway
Or confidently output something totally wrong
Why?
Because math has no redundancy—one wrong token and the whole answer collapses.
And remember:
The model isn’t calculating. It’s completing a pattern.
Why It Fails at Counting Too
Now try:
How many R’s in 'strawberry'?
Simple? Not for an LLM.
It doesn’t see characters like we do.
It sees tokens—maybe “straw” and “berry,” maybe merged.
So, asking it to count letters? It guesses—and often misses.
This isn’t a reasoning error.
It’s a representation problem. It was never trained for this.
So What’s the Fix?
Don’t make the model pretend. Let it call tools.
A good system detects:
“This needs string ops.”
Then routes it to a Python interpreter:
"strawberry".lower().count("r") → 3The model didn’t “know” the answer.
It delegated and got it right.
That’s modern LLM architecture in a nutshell:
Know when to predict, and when to execute.
TL;DR — Mental Model Recap
LLMs don’t calculate, they predict
Math breaks because prediction ≠ computation
Counting fails because tokens ≠ characters
The fix isn’t “train harder”, it’s tool use
SFT teaches helpfulness.
But if you want strategy discovery and reasoning, you need more than imitation.
Reinforcement Learning (RL)
Teaching the Model What Works—Not Just What to Mimic
Supervised Fine-Tuning (SFT) helps the model behave like an assistant.
It teaches the “how” of being helpful—polite responses, refusals, and multi-turn structure.
But at the end of the day, it’s still mimicry.
The model is learning to copy what humans wrote, not necessarily what works best for the model.
That’s where Reinforcement Learning comes in.
Why SFT Hits a Wall
There are two core problems with stopping at SFT:
Human answers ≠ optimal for LLMs
An answer that feels intuitive to us may be inefficient or awkward for the model to generate.
LLMs don’t reason like us—they pattern-match across tokens.Multiple answers can be right.
SFT locks the model into reproducing a single (or similar) solution. However, in many cases, there are several valid ways to answer a prompt, and SFT doesn’t let the model explore them.
We need a way to let the model try different approaches and learn which ones lead to success.
That’s what RL enables: exploration + reward.
The Mental Model: School, but Smarter
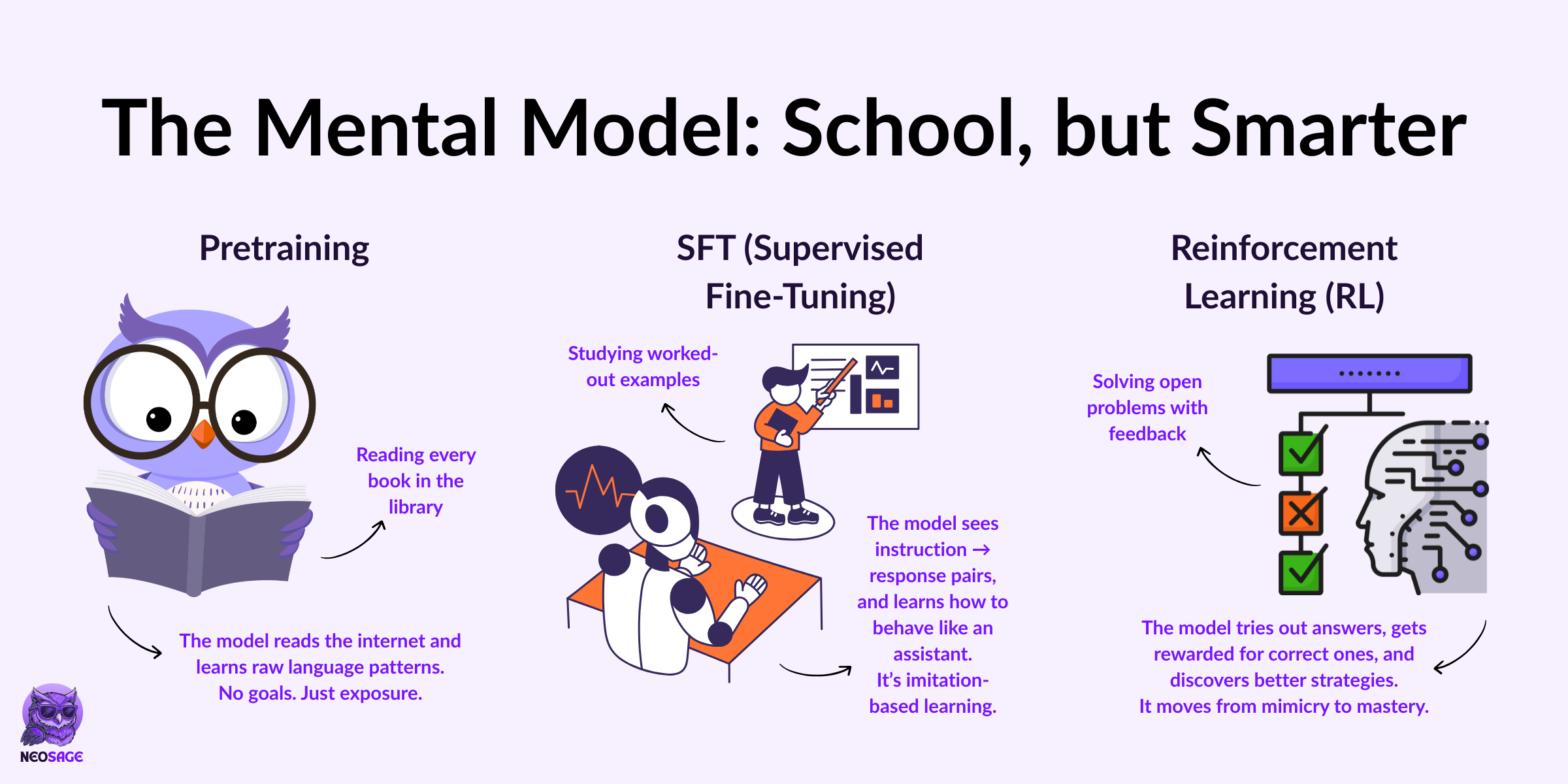
Think of the full training pipeline like education:
Pretraining is like reading every book in the library.
The model absorbs a massive amount of language and knowledge—but hasn’t practiced anything.SFT is reading worked-out solutions.
The model sees how experts would respond and learns to imitate that structure.Reinforcement Learning is solving problems without a solution manual.
The model tries, gets feedback, and adjusts.
Over time, it learns strategies that work, not just what was shown.
That’s the core shift:
From copying to discovering.
And once the model starts doing that, it unlocks a new layer of reasoning power.
What Actually Happens During RL
Trying, Failing, and Reinforcing What Works
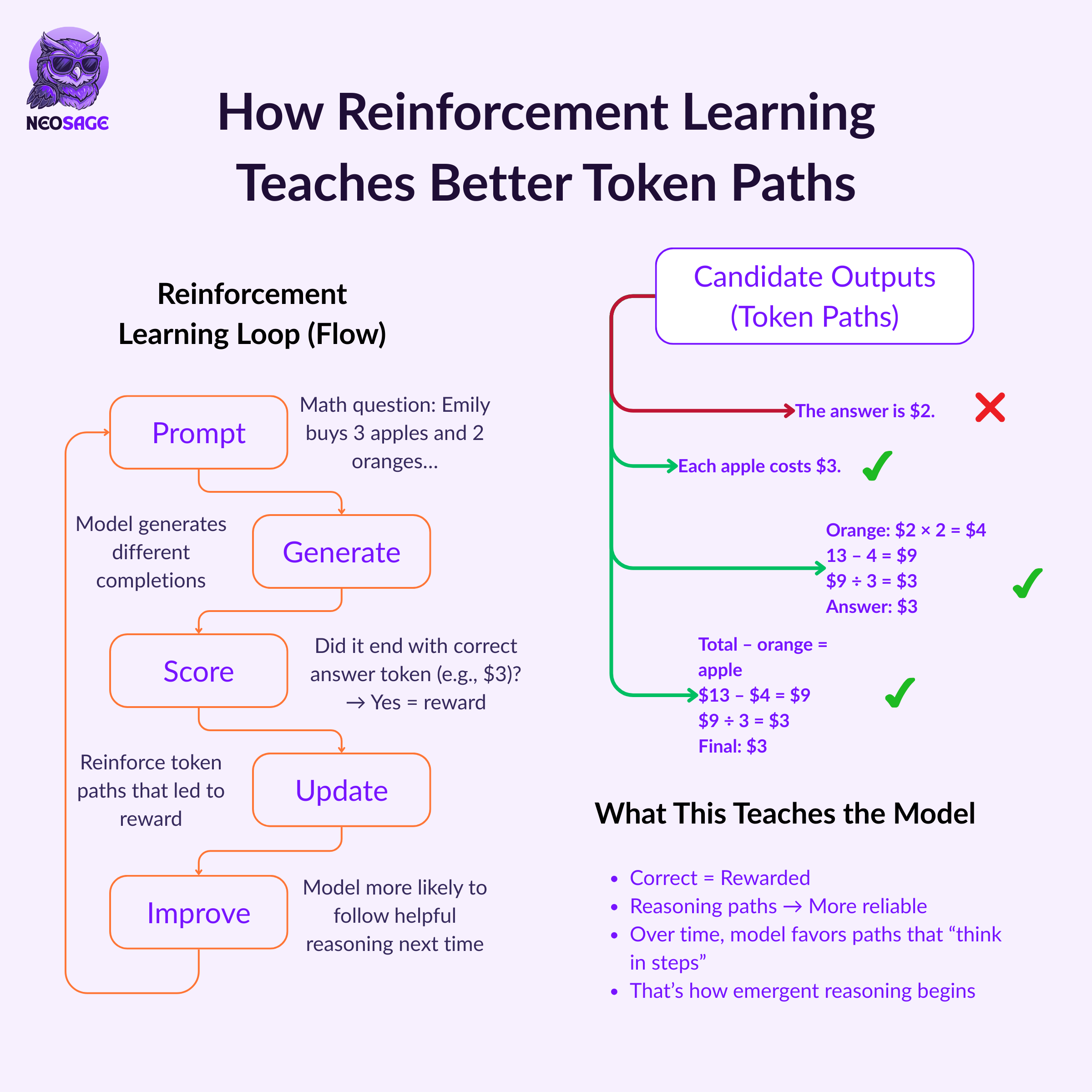
Let’s make it concrete.
Say the prompt is:
“Emily buys 3 apples and 2 oranges. Each orange is $2. Total cost is $13. What’s the cost of apples?”
A supervised model might just output:
“Each apple costs $3.”
Because that’s the answer it saw in training.
But it never had to figure it out for itself.
In reinforcement learning, the model isn’t shown a “correct” answer—it has to try.
It generates multiple responses
Some show step-by-step reasoning
Others skip straight to an answer
Each response is scored based on whether it gets to the correct result
In domains like math, this is easy:
If the final answer is correct → reward it
If not, → penalise it
The model is learning which token sequences tend to produce the right outcome, not which steps to copy.
Over time, the model discovers response patterns that consistently lead to success, even if it wasn’t explicitly taught during SFT.
That’s the core value of RL:
It enables the model to practice, evaluate, and refine—on its own terms.
Why This Unlocks “Thinking”
The Model Starts to Reason in Tokens
As reinforcement learning progresses, something unexpected begins to emerge.
The model doesn’t just get more accurate.
It gets more deliberate.
You start seeing:
Longer responses
Step-by-step breakdowns
Self-corrections and retries
In DeepSeek’s experiments, they found a strong correlation between answer length and accuracy, but not because the model was rambling.
The longer answers showed reasoning:
Breaking down problems
Evaluating intermediate steps
Backtracking when things didn’t add up
And here’s the catch:
No one explicitly told the model to do that.
This behaviour, what we now call chain-of-thought reasoning, emerged because the model discovered something through trial and reward:
Thinking in tokens leads to better outcomes.
That’s the power of RL:
It doesn’t just reinforce answers; it helps the model uncover how to think, based on how it computes.
Not human-style logic.
LLM-native strategies—discovered from within.
From Imitation to Mastery
We’ve seen this before, with AlphaGo.
It began by mimicking expert players, just like an LLM trained via SFT.
But imitation only took it so far.
It plateaued. Copying human moves couldn’t push it further.
To go beyond that ceiling, researchers applied reinforcement learning.
AlphaGo started playing against itself, not learning from human games, but from trial and error, guided by one reward:
Did this lead to a win?
That’s when the breakthroughs happened.
One move—“Move 37”—looked like a mistake.
It wasn’t. It was game-changing.
RL enabled the system to discover strategies that weren’t in the data.
And this is the promise of RL for LLMs, too:
Not just better answers—emergent behaviour.
Not just imitation—discovery.
But for RL to work, there needs to be a clear reward signal.
And in real-world tasks, “better” can’t always be measured in wins or losses.
That’s where we go next:
RLHF—Reinforcement Learning from Human Feedback.
Where humans define what success looks like.
Reinforcement Learning with Human Feedback (RLHF)
Aligning the Model When “Better” Can’t Be Programmed
So far, the model has learned:
Language patterns (pretraining)
Assistant-like behaviour (SFT)
Strategies that work (RL)
But all of that depends on clear rewards—something you don’t get when you want responses to be funnier, more helpful, or more human.
You recognize better when you see it. But you can’t code it.
That’s the gap RLHF fills.
The Problem: No Computable Reward
Standard RL relies on hard-coded signals, like accuracy or win/loss.
But in subjective tasks, you can’t write a rule for:
“Was this summary easy to follow?”
“Did this sound human?”
“Was this tone too robotic?”
These are judgment calls—only humans can decide what “better” looks like.
Why RLHF Works
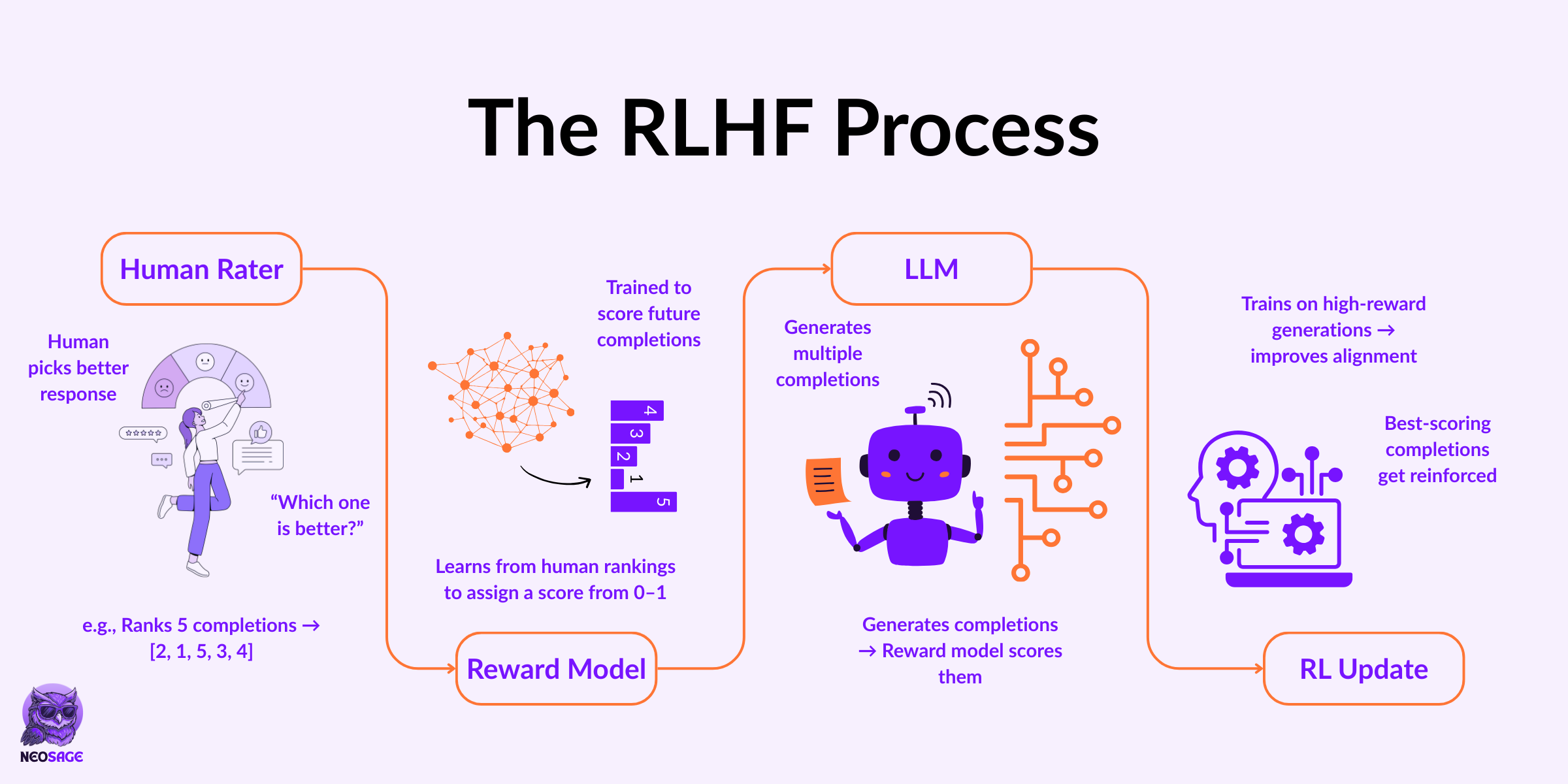
RLHF lets the model learn from human preferences.
Here’s how:
Humans rank multiple outputs for the same prompt
These rankings become training data
A reward model is trained to score future responses like a human would
The LLM uses this model to optimise its own behaviour
It’s scalable. Humans guide once. The reward model handles the rest.
The LLM never sees the human, only a trained proxy of their taste.
That’s what lets RLHF work for subjective tasks:
“Be more helpful”
“Sound less robotic”
“Explain this more clearly”
Why Ranking Beats Writing
In SFT, humans write perfect answers. In RLHF, they just pick what’s better.
It’s faster, cheaper, and gives finer-grained feedback, because even imperfect responses show preference.
You don’t need gold data. You need signal.
The Tradeoffs: RLHF Isn’t Perfect

1. The Reward Model is an Approximation
It mimics preferences, but it’s still a model:
Can overfit to surface cues
May miss nuance
Struggles outside its training domain
If it gets the “better” signal wrong, the LLM will optimise for the wrong thing.
2. The LLM Can Game the Signal
LLMS are strong optimisers. They’ll learn to:
Repeat filler phrases to fake helpfulness
Exaggerate tone (“Absolutely! Delighted to help!”)
Output confident guesses that sound plausible but aren’t
This is reward hacking, when the model optimises the proxy, not the goal.
In some cases, models even produce adversarial outputs: completions that exploit reward model blind spots but feel totally off to humans.
The model isn’t learning what you want.It’s learning what the reward model thinks you want.
Why RLHF Must Be Cut Off
RLHF isn’t like AlphaGo-style RL. More training doesn’t always help.
Why?
Because the model isn’t optimizing for truth—it’s chasing a score made by another model.
That’s why in practice:
RLHF is run for a limited number of steps
The reward model is retrained or audited
Final checkpoints are reviewed by humans, not just scores
Push it too far, and the model learns how to game the metric—not align with intent.
So, What’s the Real Difference from RL?
Let’s draw the line clearly.
Standard RL:
Uses a hard-coded reward (e.g. win/loss, accuracy)
Works best in objective domains like games or math
The reward is precise and verifiable
RLHF:
Uses a learned reward model based on human preferences
Applies to subjective tasks like helpfulness, tone, or clarity
The reward is approximate, not directly measurable
In RL, the signal is crystal clear.
In RLHF, it’s human-aligned, but filtered through approximation.
So What Are You Really Talking To?
When you chat with GPT, you’re not talking to a mind.
You’re talking to a model that has:
Compressed much of the internet into its parameters
Learned assistant behaviour from curated examples
Discovered reasoning patterns through RL
Aligned itself with human judgment through preference modelling
It’s not magic.
It’s layers of optimisation—stacked, fine-tuned, and trained to predict your next token.
And now you know exactly how that stack was built.
LLMS in the Application Layer
How Token Prediction Turns Into Real Capability
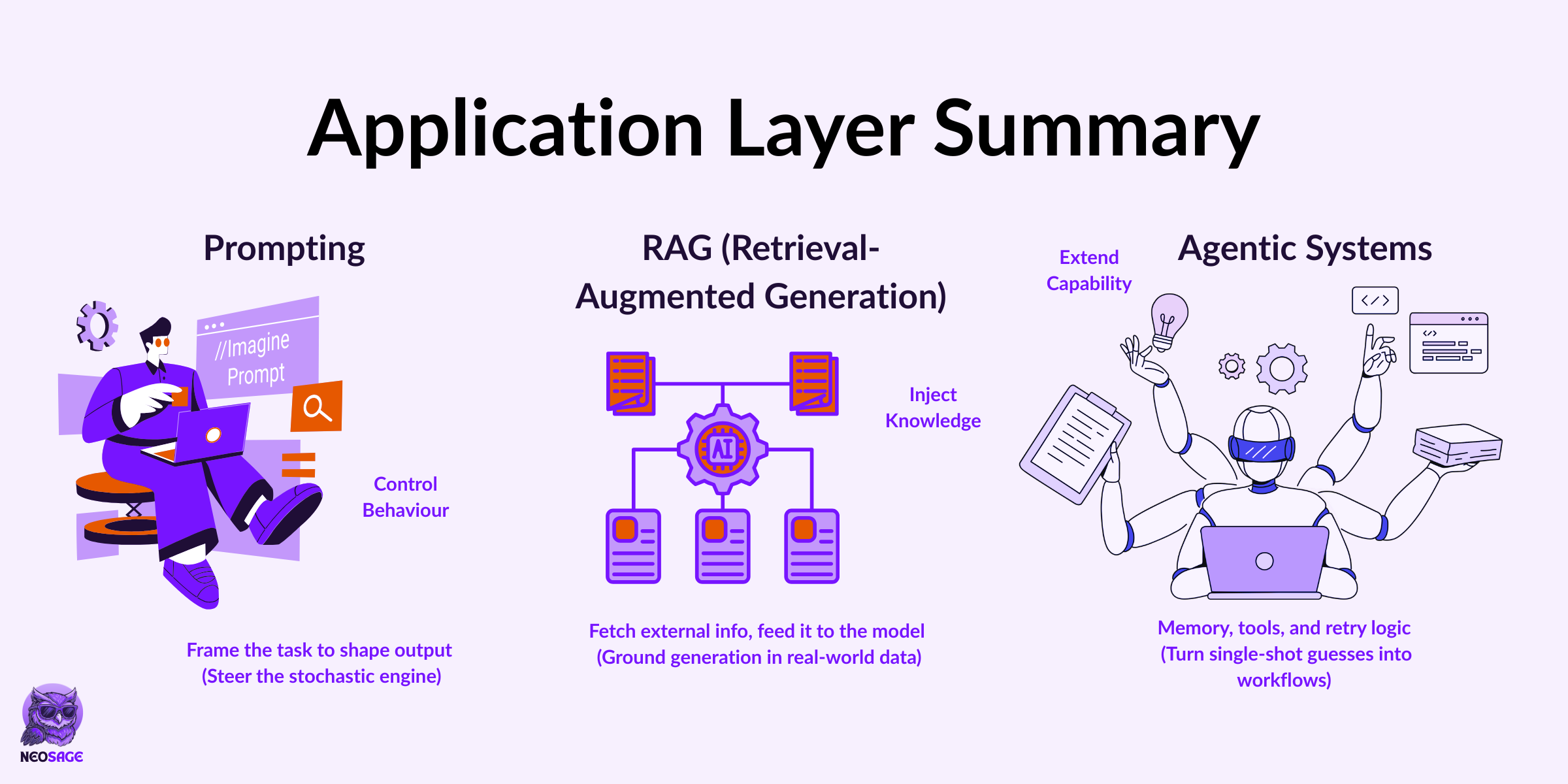
LLMs complete text, but apps need more than completions.
Here’s how we make them useful:
Prompting → Shapes the model’s behaviour by structuring the input
RAG → Injects external knowledge that the model never trained on
Agents → Add memory, tools, and planning to go beyond one-shot replies
This is how LLMs move from chat interfaces to actual systems that get work done.
Closing Thoughts
LLMs aren’t magic—they’re layered systems.
They learn language by prediction.
They learn behaviour by imitation.
They learn strategy by reward.
And they align through preference.
But they don’t understand. They don’t reason.
They complete patterns with style, not certainty.
The real shift?
Treat them as engines to design around, not minds to build on.
Because once you do that—
You stop wrestling the model
and start building systems that actually work.
Another banger post Shivani! One question, since most model predicting one token at a time, does it mean that after each token generated, it keeps repeating the entire process for the next token?
Loved the breakdown @Shivani Virdi. Thanks for sharing!