

Inside DeepSeek-R1: A Masterclass in Incentivising Intelligence
What DeepSeek-R1 really teaches us: how to build models that learn, align, and evolve — without millions of labels.

You’ve probably seen the benchmarks.
Open weights. Performance on par with OpenAI’s o1 series models
People were stunned.
Investors even started questioning OpenAI’s moat — stocks dipped.
But that’s not what makes DeepSeek-R1 remarkable.
Not really.
What actually matters — and what almost nobody talked about — is how it got there.
Because DeepSeek-R1 isn’t just a better-trained model.
It’s a blueprint for how to engineer intelligence into systems that were never taught what reasoning looks like.
No massive supervised dataset.
No army of human annotators.
No fancy process reward models.
Just a series of training choices that, when you look closely, form a system-level masterclass in making language models do more than predict tokens.
In this issue, I’ll walk you through the exact architecture, training loop, and lessons from the DeepSeek-R1 paper — not just to admire what they built, but to understand what we can borrow.
Because if your work involves LLMs that need to reason, align, or evolve over time —
DeepSeek-R1 isn’t just a model worth studying.
It’s a system worth stealing from.
Why DeepSeek-R1 Mattered So Much, So Fast
When DeepSeek-R1 dropped, the headlines focused on one thing: performance.
79.8% on AIME 2024.
97.3% on MATH-500.
96.3 percentile on Codeforces.
On par with OpenAI’s o1-1217 — OpenAI’s ‘then’ best reasoning model
That alone was enough to cause a stir.
If you’re not big on benchmarks, don’t worry because me neither. Benchmark reports should always be taken with a big rock of salt. (Yes, rock salt. :P)
But what really jolted the industry was the cost-efficiency behind those numbers.
DeepSeek didn’t just release open weights — they released MoE architecture, inference-optimised routes, and a 671B parameter model that activates only 37B per forward pass.
The result? Comparable output quality at a fraction of the inference cost — and that did reflect in OpenAI’s stock price.
But even that isn’t the full story.
What makes DeepSeek-R1 impossible to ignore, especially for engineers, is this:
It wasn’t trained the way models are usually trained.
There was no massive supervised alignment stage.
No instruction tuning on millions of curated tasks.
No handcrafted demonstrations — just reward structures that made reasoning emerge on its own.
Instead, DeepSeek-R1 was built to answer a very different question:
Can you train a language model to reason, not by showing it what reasoning looks like, but by rewarding it when it gets it right?
That single bet is what makes this system so relevant.
Because the pipeline that emerged from it isn’t just academically novel — it’s a practical rethink of how to get reasoning from a model without incurring massive overhead.
And if you’re in the business of building applied LLM systems — whether that’s fine-tuning smaller models, training agents, or aligning behaviour — that question is your question too.
So from this point on, we stop looking at R1 as “a strong open model.”
And start looking at it as a system architecture — one that happens to make strong reasoning emerge with lower training burden, lower inference cost, and far better alignment with engineering constraints.
Let’s unpack that system.
Note for the reader:
This breakdown has been intentionally kept accessible, not to simplify the work, but to sharpen your intuition. The goal isn’t just to understand DeepSeek-R1, but to update your mental model so you can take these ideas to the application layer.
The Core Bet — Can Reasoning Be Incentivised, Not Taught?
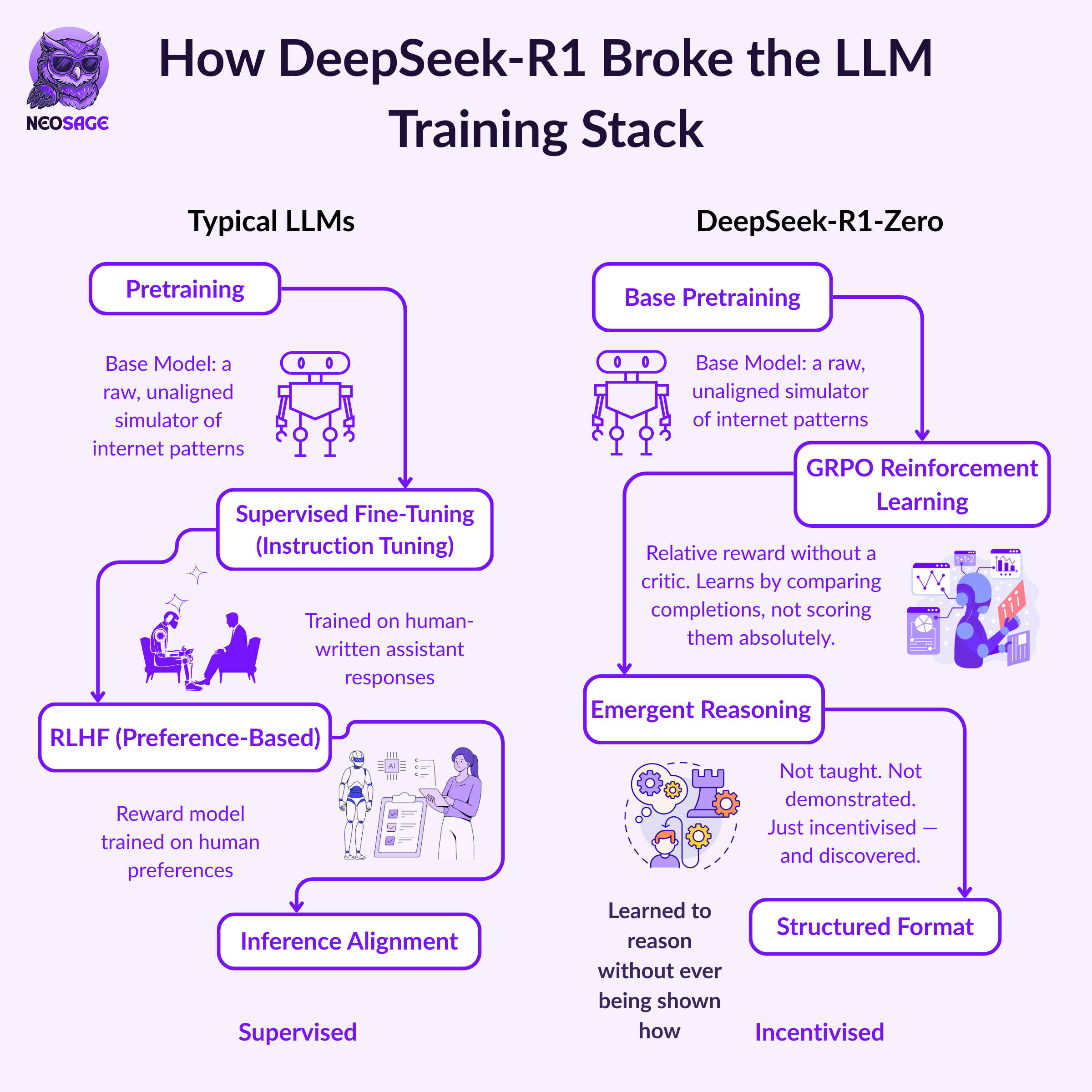
Most modern LLMs are trained in two broad stages:
Pretraining — on massive amounts of raw text, predicting the next token across everything from books to code to forums
Post-training / alignment — where the model is fine-tuned to be helpful, truthful, and aligned with human intent
If interested in knowing more about how LLMs are trained, read these issues:


That second stage is where most of the nuance comes in — and where most models start to diverge.
The typical pipeline looks like this:
Start with a base model — a pretrained LLM that’s good at next-token prediction, but still brittle or unhelpful in practice
Apply Supervised Fine-Tuning (SFT) — feed it carefully curated examples of “good completions” for prompts, and nudge it toward copying that behaviour
Optionally, add a reward model trained on human preferences, then use reinforcement learning (usually PPO) to further optimise
SFT, in particular, became the backbone of alignment strategies because it's simple and data-efficient:
You just show the model enough “good completions” and let it imitate the output.
But that approach comes with limits.
Because while it can teach the model what correct answers look like,
It doesn’t necessarily help it understand how to think through the problem, especially in domains like math, logic, or program synthesis.
You end up with models that pattern-match well, but can’t adapt their process when the pattern changes.
And that’s exactly the gap DeepSeek set out to address.
Instead of building a reasoning model by showing it what reasoning looks like,
they asked a much more interesting question:
What if we just rewarded the model whenever it reasoned correctly — and let it figure out the rest on its own?
That’s the bet behind DeepSeek-R1-Zero.
No demonstrations. No handcrafted completions.
Just a base model, a carefully structured training loop, and a reward signal grounded in outcomes.
And surprisingly, it worked.
Here’s how:
They weren’t optimising for final answers alone.
They were incentivising process, behaviour patterns that resemble reasoning:
longer chains of thought, structured output, internal verification, and the correct final answer.
That meant two things:
The reward signal had to be grounded — e.g., for math, the model had to output its final answer in a strict format so correctness could be programmatically verified. For code, it had to compile and pass test cases.
The reasoning process had to be detectable, so they enforced a structured template:
<think>for intermediate reasoning,<answer>for final result
This wasn’t prompting. It wasn’t fine-tuning on examples.
It was incentive engineering — shaping the model’s behaviour by designing a reward system where reasoning becomes the optimal strategy.
To do this, they used Group Relative Policy Optimisation (GRPO) — a reinforcement learning approach that doesn’t require a separate critic network.
Instead of relying on external evaluation, GRPO works by sampling a group of outputs for each question and scoring them relative to one another.
The model learns by reinforcing whichever outputs perform best — a kind of internal competition — without needing labelled comparisons or reward models trained on preferences.
We’ll go deeper into how GRPO works in the next section. But the key idea here is this:
DeepSeek didn’t teach the model how to reason.
They built a system where reasoning was the best strategy for getting rewarded.
And that shift — from instruction to incentive — unlocks a fundamentally different kind of training pipeline.
If reasoning can emerge through reinforcement alone,
you’re no longer limited by how many examples you can label.
You’re only limited by how well you can define success.
That’s what makes DeepSeek-R1-Zero so important.
It’s not just a training variant.
It’s a new way to think about how intelligent behaviour gets built.
Inside R1-Zero’s Training Loop — How Reinforcement Actually Worked
To train DeepSeek-R1-Zero, the team didn’t start with labelled examples of “good” reasoning.
They started with a pretrained base model — DeepSeek-V3-Base — and no additional supervised data.
This base model was trained like most foundation models: on next-token prediction over large-scale web data.
At this stage, it had no alignment, no formatting consistency, and no reasoning skill beyond pattern matching.
The DeepSeek team didn’t fine-tune it on curated examples.
Instead, they designed a reinforcement learning loop that rewarded the outcomes of good reasoning and let the model figure out the process on its own.
This was the core design shift:
Don’t show the model how to reason. Just define what success looks like and let it discover reasoning as the optimal strategy.
Let’s walk through how this worked.
The Setup: From Base Model to Self-Improving System
The reinforcement setup had three main components:
A prompt dataset — questions/tasks covering math, coding, science, and logic
A reward function — that could score completions automatically
An RL algorithm — GRPO (Group Relative Policy Optimisation)
The model generated multiple completions for each prompt, and GRPO was used to update the model toward the better-performing ones.
But what makes GRPO different, and especially suited for this, is that it doesn’t require a critic model.
Let’s unpack that.
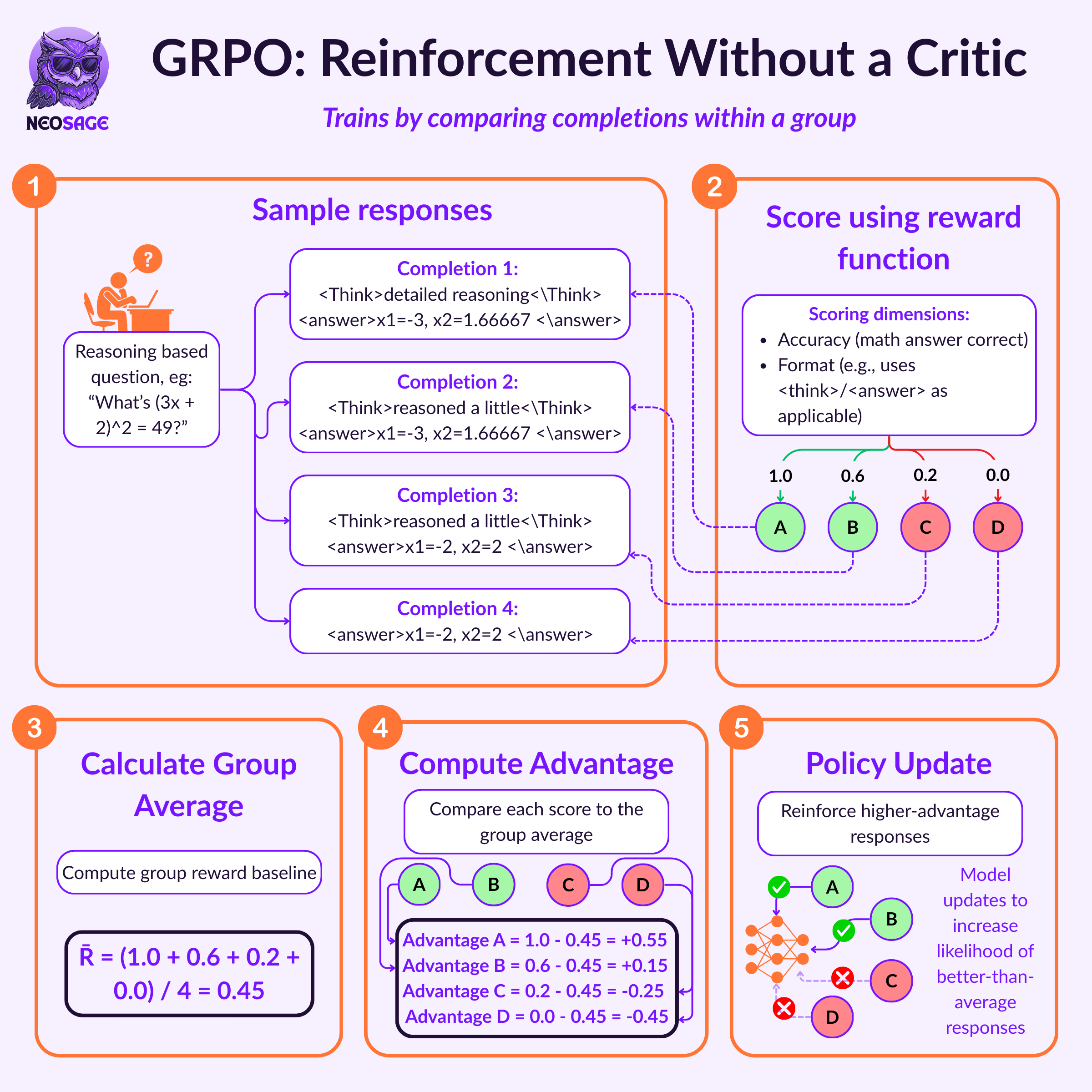
GRPO: What Changed and Why It Matters
Most reinforcement learning setups for LLMs (like PPO, used in RLHF) rely on a critic model — a second neural network trained to estimate how good an output is.
That’s expensive to train, hard to stabilise at scale, and can introduce noise if the critic itself is misaligned.
GRPO (Group Relative Policy Optimisation) drops the critic completely.
Instead, it scores outputs relative to each other within a group, using just a reward function — no second network.
Here’s the flow:
For each prompt, the model samples K outputs
Each output is scored with a rule-based reward
The group’s mean reward becomes the baseline
Each output’s advantage is:
\(A_{jk} = R_{jk} - \bar{R}_j$\)where:
R_{jk}is the reward for output k in prompt j\bar{R}_j is the mean reward for all K outputs for that prompt
This replaces PPO’s value function with group-level comparison.
And instead of needing a value estimate, GRPO just says:
“Which completions were better than average?”
Then it nudges the model to prefer those, using a KL penalty to stay stable.
The full update loss looks like:
Why this matters for models like DeepSeek-R1:
✅ It’s stable across large batch sizes
✅ It’s cheap — no critic to maintain
✅ It scales — GRPO was used to train DeepSeekMath with 64 completions per prompt
And most importantly, it works beautifully in domains where you can verify outputs, like math and code. That’s what made it the backbone of DeepSeek-R1-Zero.
GRPO doesn’t teach by example.
It teaches by comparison and lets the model discover the better path.
The Reward Functions: How Reasoning Was Incentivised
DeepSeek-R1-Zero used two reward signals, both programmatic and fully automatable:
Accuracy Reward (These examples are for understanding purposes and not sourced verbatim from the original paper)
For math tasks: reward = 1 if the final answer was correct (e.g., matched a boxed number), 0 otherwise
For code: reward = 1 if the code compiled and passed test cases, 0 otherwise
For logic/science: multiple-choice answer correctness or rule-based consistency checks
Format Reward
Every output had to follow a fixed structure:
<think> reasoning steps </think> <answer> final answer </answer>Outputs that violated the format were scored 0 and ignored
This structure wasn’t decorative — it was essential.
The <think> section forced the model to externalise intermediate reasoning.
The <answer> section made verification easy and automated.
Together, these two rewards created a simple loop:
If you think clearly and answer correctly → you’re reinforced
If you hallucinate, skip steps, or break format → you’re ignored or penalised
And with GRPO driving learning, the model slowly evolved to prefer the reasoning strategies that led to high scores, even without seeing a single example of what “good reasoning” looked like.
The Aha Moments: What Emerged in the Process

This is where it gets interesting.
As training progressed, the model didn’t just get more accurate.
It started to behave as if it understood the value of thinking.
In the paper, the authors show examples like this:
<think>
Wait, wait. Wait. Let me try a different method...
</think>
<answer>
[Correct boxed result]
</answer>This wasn’t cherry-picked.
This pattern of reevaluation, error checking, and iterative problem solving emerged purely from reinforcement.
The model began:
Taking longer paths to answers
Writing self-checking logic
Rephrasing its own steps mid-generation
Learning how to reason because it was the most reliable way to get reward
One intermediate checkpoint had already achieved:
71% Pass@1 on AIME-2024 (up from 15.6%)
86.7% with majority voting — matching OpenAI’s o1-0912
All without ever seeing a supervised CoT (Chain of thought) example.
This wasn’t just scaling token prediction.
This was behaviour change — learned from first principles.
Where It Fell Short
But R1-Zero wasn’t usable out of the box.
Despite its reasoning capability, it had critical flaws:
Poor readability: reasoning traces were verbose and messy
Language mixing: often switched between English and Chinese mid-output
No general instruction following: it wasn't aligned to be helpful or polite, just to reason
That’s why DeepSeek-R1 introduced a second-stage cold-start + RL stack.
But the point was proven: the model didn’t need instruction tuning to learn how to reason.
It needed a well-designed feedback loop.
Why This Loop Matters
This training loop gave us the first open proof that:
A model can develop reasoning behaviours purely from reinforcement
You don’t need to hardcode thought — you can incentivise it
GRPO offers a scalable, low-friction alternative to PPO and RLHF-style setups
Reasoning isn’t a dataset problem — it’s a system design problem
And for engineers building alignment stacks, agent loops, or low-cost reasoning assistants —
That opens a whole new frontier.
Because now, you don’t need to start with answers.
You just need to define the kind of outputs you want and design a loop that rewards getting there.
From R1-Zero to R1 — Building a System That Aligns
By the end of R1-Zero, DeepSeek had something rare:
A model that could reason, without ever being shown how.
Through reinforcement alone, it had learned to chain thoughts, reevaluate steps, and converge on answers.
But it couldn’t present those answers clearly. It couldn’t follow instructions. And it didn’t know how to speak with the user in mind.
It was a prototype for reasoning, not a system ready to deploy.
The outputs were verbose. The formatting was unstable. The language switched mid-sentence.
And beyond STEM-style tasks, it struggled to handle general prompts — writing, summarisation, chat, translation.
R1-Zero made reasoning emerge.
The next challenge was: how do you keep that reasoning and shape it into something useful?
That’s what DeepSeek solved with R1.
But they didn’t solve it with more of the same.
They didn’t stack another RL pass or throw in alignment data midstream.
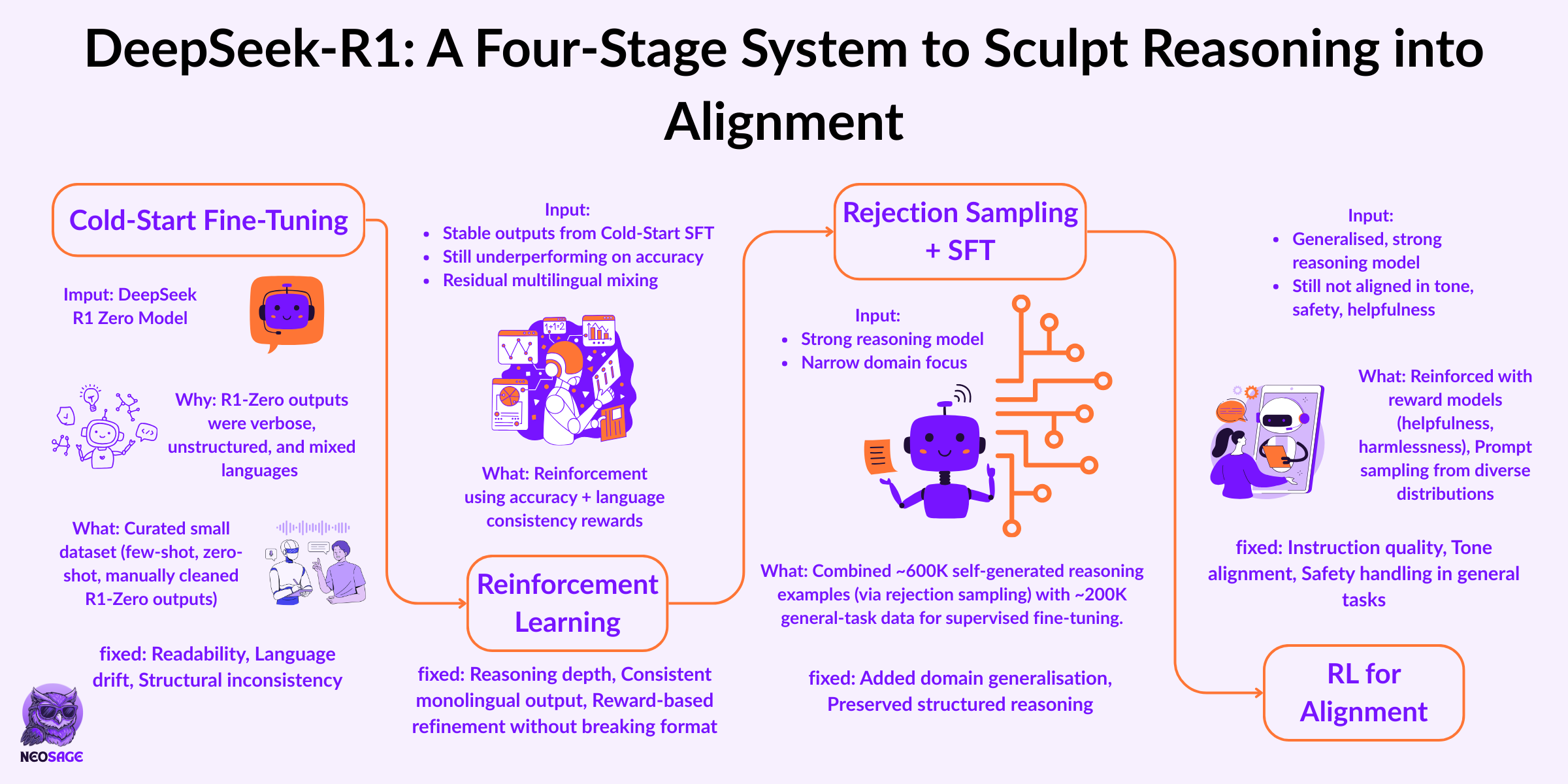
They built a multi-stage refinement pipeline, where each phase:
Solved a real, traceable failure from the one before
Preserved the capabilities that had already emerged
Introduced exactly what was needed — no more, no less
In the next four stages, they transformed a raw reasoner into a structured, general, aligned system, without breaking the behaviour they had trained from scratch.
Let’s break that pipeline down — one stage at a time.
Stage 1: Cold-Start Fine-Tuning
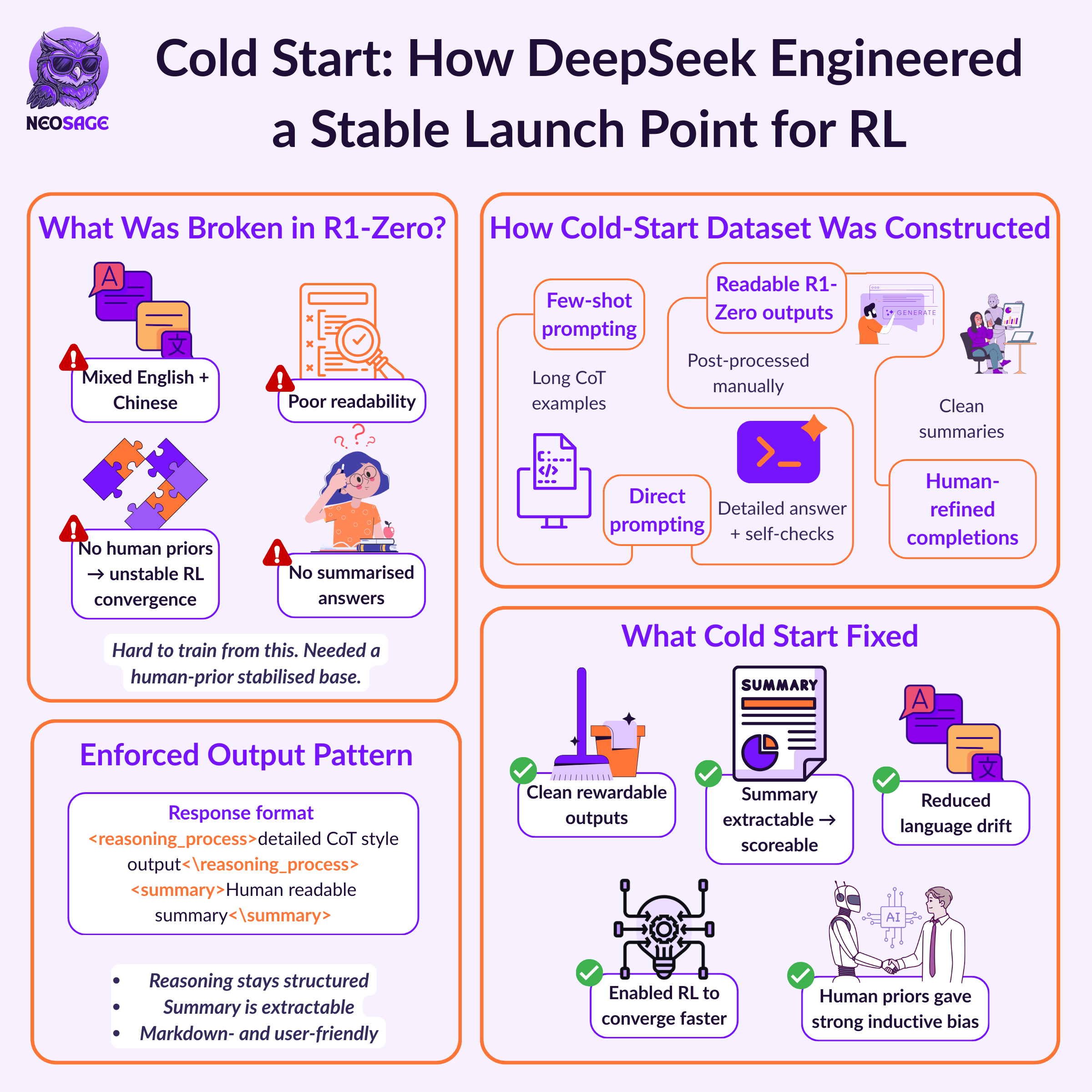
Goal: Fix readability, enforce output structure, and prevent language mixing.
R1-Zero’s outputs followed a basic structure:
<think> reasoning steps </think>
<answer> final result </answer>This worked for reward scoring, but failed in practice. The model’s completions showed:
Inconsistent or incoherent formatting
Excessive verbosity
Frequent English–Chinese language switching
No clear, summarised final answer
To stabilise the output, DeepSeek curated a cold-start supervised dataset composed of:
Few-shot prompted completions
Zero-shot generations
Manually refined outputs from R1-Zero
They introduced a new output structure:
<reasoning_process> structured reasoning steps </reasoning_process>
<summary> user-facing final answer </summary>
This format improved outputs by:
Separating internal logic from final messaging
Constraining tone and fluency
Removing ambiguity in how the model should present conclusions
By showing it labelled dataset of good completions
The model was fine-tuned briefly on this dataset.
Not to teach new reasoning, but to create a stable interface between internal CoT and external output.
This format became the foundation for subsequent reward modelling and scoring.
Stage 2: Reasoning-Oriented Reinforcement Learning
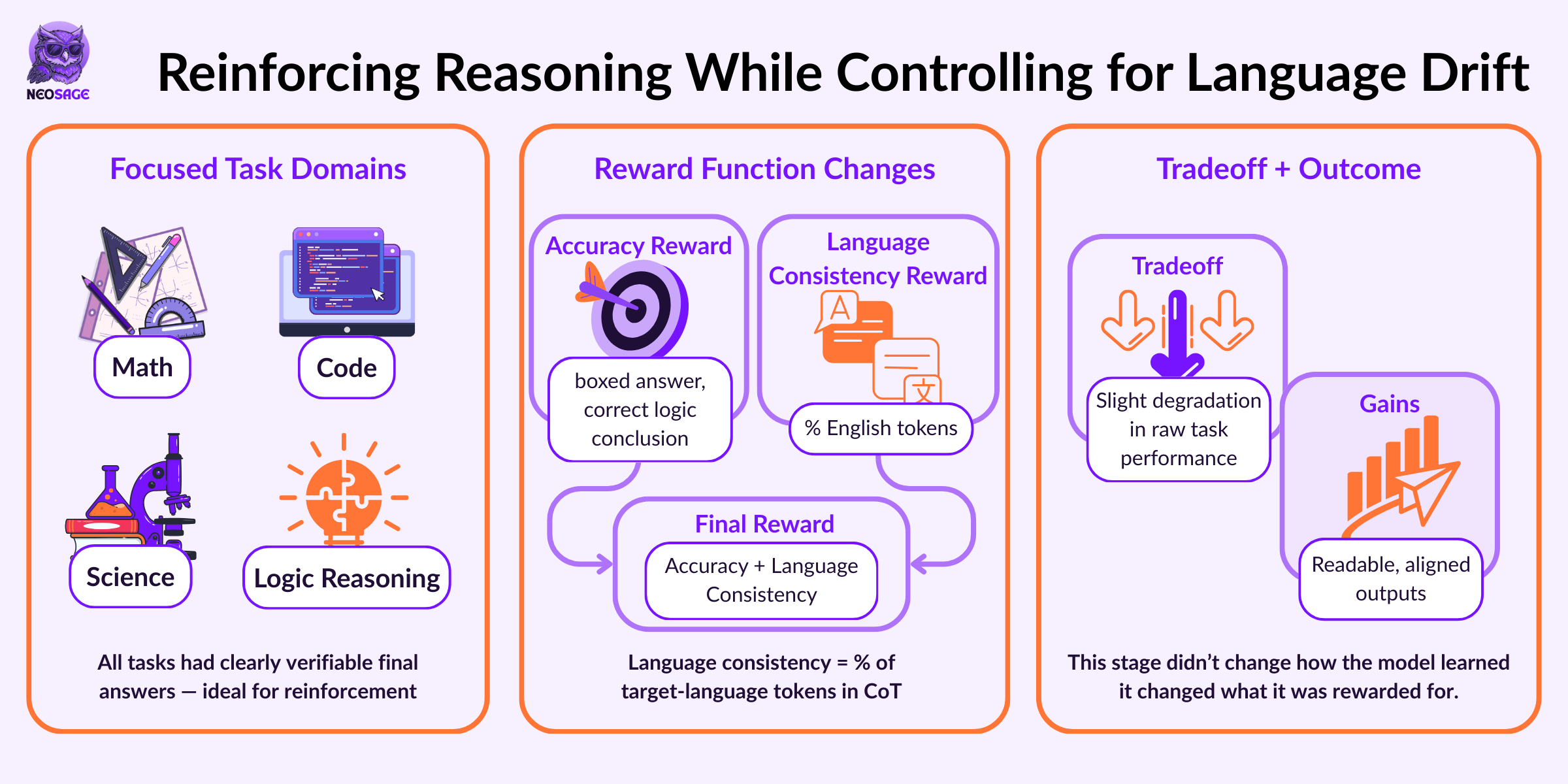
Goal: Improve reasoning performance and enforce language consistency using structured RL.
With output structure stabilised through cold-start fine-tuning, DeepSeek returned to reinforcement learning to strengthen reasoning performance.
While the model could now follow the <reasoning> and <summary> format, it still exhibited two key issues:
Incomplete reasoning convergence — performance on math, coding, and logic tasks had room to improve
Language mixing — particularly between English and Chinese, which impacted clarity and evaluation
To address both, DeepSeek applied another round of large-scale reinforcement learning, using the same GRPO (Group Relative Policy Optimisation) algorithm as in R1-Zero.
What was done
In this stage, the reward function was updated to include two components:
Reasoning Accuracy Reward
Based on whether the final result was correct (e.g., boxed answer correctness in math, compilation and test success in code)
Language Consistency Reward
Measured by the proportion of tokens in the target language
Outputs with mixed-language tokens were penalised
This reward function was applied over reasoning-intensive tasks — specifically math, science, code, and logic — and training continued until convergence on those benchmarks.
What this enabled
This stage further strengthened the model’s reasoning ability — now with stable formatting, improved correctness, and monolingual output — without introducing alignment or general-purpose behaviours yet.
By reinforcing under tightly defined reward signals and clean output structure, the model was now ready to scale into broader domains.
Stage 3: Rejection Sampling + Supervised Fine-Tuning
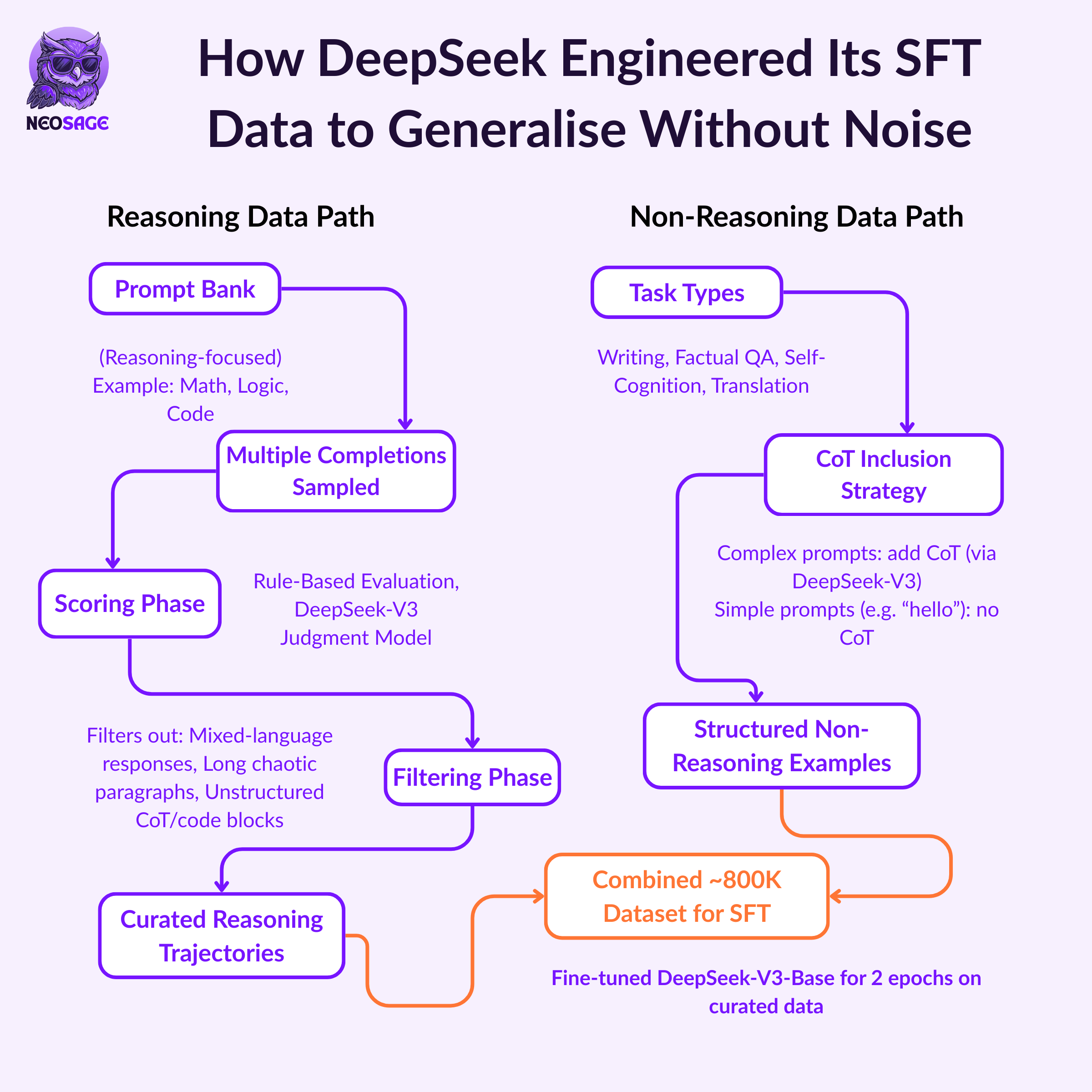
Goal: Broaden model capability beyond reasoning tasks, while preserving structure and quality.
After reinforcement learning in Stage 2, the model demonstrated strong performance on reasoning-heavy benchmarks, such as math, coding, science, and logic.
But it was still limited to those domains. It lacked general-purpose abilities across:
Writing and role-play
Factual question answering
Translation
Dialogue and open-ended tasks
To expand coverage without compromising reasoning quality, DeepSeek constructed a new supervised dataset, composed of both:
Self-generated high-quality reasoning examples, and
General-task examples from DeepSeek-V3’s alignment pipeline
What was done
The new training set included approximately 800K samples, split as follows:
Reasoning Data (~600K)
Generated by running prompts through the Stage 2 model checkpoint
For each prompt, multiple completions were sampled
Each completion was scored using:
Rule-based rewards (correctness, format)
Judgment models from DeepSeek-V3
Only the highest-rewarded completions were kept, using rejection sampling
Non-Reasoning Data (~200K)
Reused from DeepSeek-V3’s SFT pipeline
Domains included:
Role-play
Factual QA
Writing
Translation
Self-cognition
CoT was selectively included using prompting or omitted for simpler queries
Output format handling
Reasoning examples retained the
<reasoning>and<summary>formatFor non-reasoning tasks, this structure was not always enforced
Some factual tasks used only
<summary>, and others followed typical chat-style instructions
This flexible formatting ensured that reasoning quality was preserved while adapting outputs to the task type.
Training configuration
The combined dataset was used to fine-tune the model for two epochs
No additional alignment rewards or reinforcement were introduced at this stage
The goal was to solidify generalisation while maintaining structured output for reasoning tasks
What it enabled
By combining curated self-generated reasoning traces with diverse, human-aligned general tasks, this stage produced a model that could:
Reason deeply
Communicate fluently
Generalise across prompt styles and domains
And it did so without erasing the carefully reinforced behaviours from prior stages.
The next step was to align it with helpfulness and safety under real-world constraints.
Stage 4: Reinforcement for Alignment and Safety
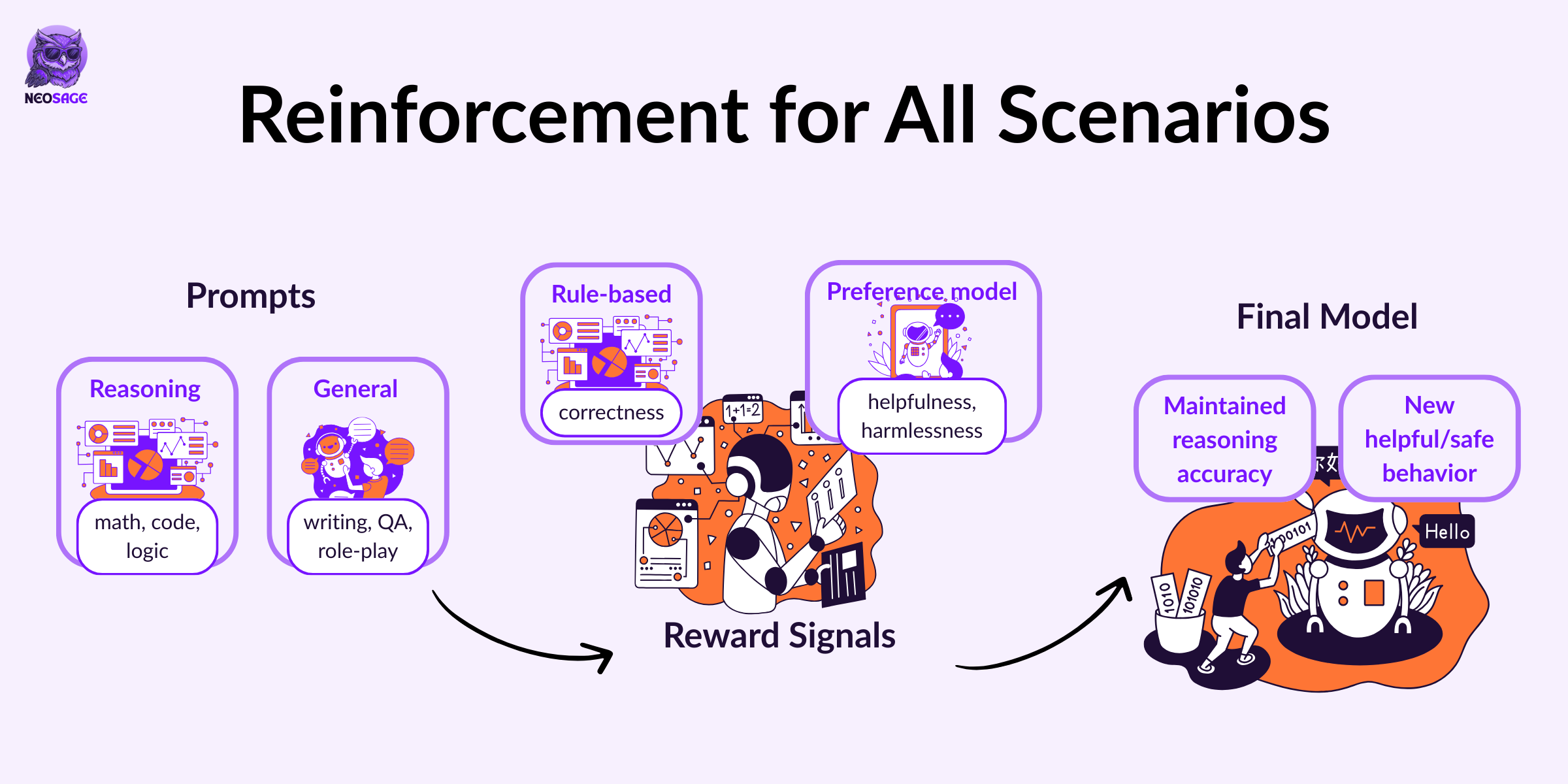
Goal: Align behaviour across general scenarios using reward models for helpfulness and harmlessness.
By the end of Stage 3, the model could reason fluently and generalise across domains, but it still lacked behavioural alignment in subjective and open-ended tasks.
It wasn’t reliably helpful. It didn’t avoid unsafe completions. It didn’t consistently reflect human intent in tasks like summarisation, chat, or instruction following.
To address this, DeepSeek introduced a final round of reinforcement learning, focused on alignment.
What was done
DeepSeek applied additional RL training using a new set of reward signals.
For reasoning tasks:
The model continued to receive rule-based rewards, as in previous stages
For general tasks:
DeepSeek used reward models from DeepSeek-V3 to capture alignment signals:
Helpfulness — evaluated over the
<summary>portionHarmlessness — evaluated over the entire response
From the paper:
“For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios.” (§2.3.4)
While the paper doesn’t specify how these reward models were trained, it makes clear that they were used to model human preferences for prompts where correctness or structure alone couldn’t define quality.
Prompts were drawn from a diverse distribution, and each was evaluated using the appropriate reward signal, depending on whether it was a reasoning or general instruction-following task.
What it enabled
This final reinforcement phase aligned the model’s outputs with human expectations, making it more helpful, more appropriate, and more consistent across real-world use cases.
With this step, DeepSeek-R1 became not just a reasoner, but a usable system that combined logical capability with structured communication, generalisation, and safety.
Distilling Reasoning — Teaching Smaller Models to Think
Goal: Transfer R1’s reasoning ability into smaller, open-weight models using SFT alone.
Once DeepSeek-R1 had been trained, the next question was:
Can its reasoning capability be transferred, not just deployed?
Instead of running expensive RL loops on every downstream model, DeepSeek explored whether smaller base models could be taught to reason by learning from R1’s behaviour directly.
This wasn’t about copying parameters — it was about teaching via output.
And it worked.
What was done
DeepSeek used the ~800K dataset created in Stage 3 — made up of high-quality reasoning and general-task examples — to distil R1 into a new series of models.
They fine-tuned several base models using supervised learning only (no reinforcement):
Qwen2.5 series: 1.5B, 7B, 14B, 32B
Llama3 series: 8B, 70B
Each of these base models was fine-tuned using the R1 dataset, capturing both its structured reasoning and generalisation behaviours.
“We fine-tune several dense models…using the reasoning data generated by DeepSeek-R1.” — §2.4
No reinforcement learning was applied during distillation.
The distilled models learned entirely by mimicking R1’s output, supervised fine-tuning on prompts and completions.
What emerged
The results showed that R1’s reasoning capability could be transferred, even without re-running the RL loop.
DeepSeek-R1-Distill-Qwen-14B outperformed QwQ-32B-Preview
DeepSeek-R1-Distill-Qwen-32B achieved:
72.6% on AIME 2024
94.3% on MATH-500
57.2% on LiveCodeBench
These models surpassed o1-mini on several reasoning-heavy benchmarks
This proved that reasoning, once made emergent in a larger model, could be replicated downstream, even in smaller dense architectures.
What it means for builders
This distillation loop wasn’t just about compressing size — it was about compressing capability.
It showed that:
Small models can reason
But only if the teacher model learned to reason first
Reinforcement learning isn’t always scalable, but its outcomes can be scaled through careful distillation
For any builder working on LLMs with limited compute, this changes the calculus.
You don’t need to start with a reasoning-capable small model.
You need a good teacher.
And if the teacher is something like R1, you might only need supervised fine-tuning to get very far.
Final Mental Models — What This Issue Leaves You With
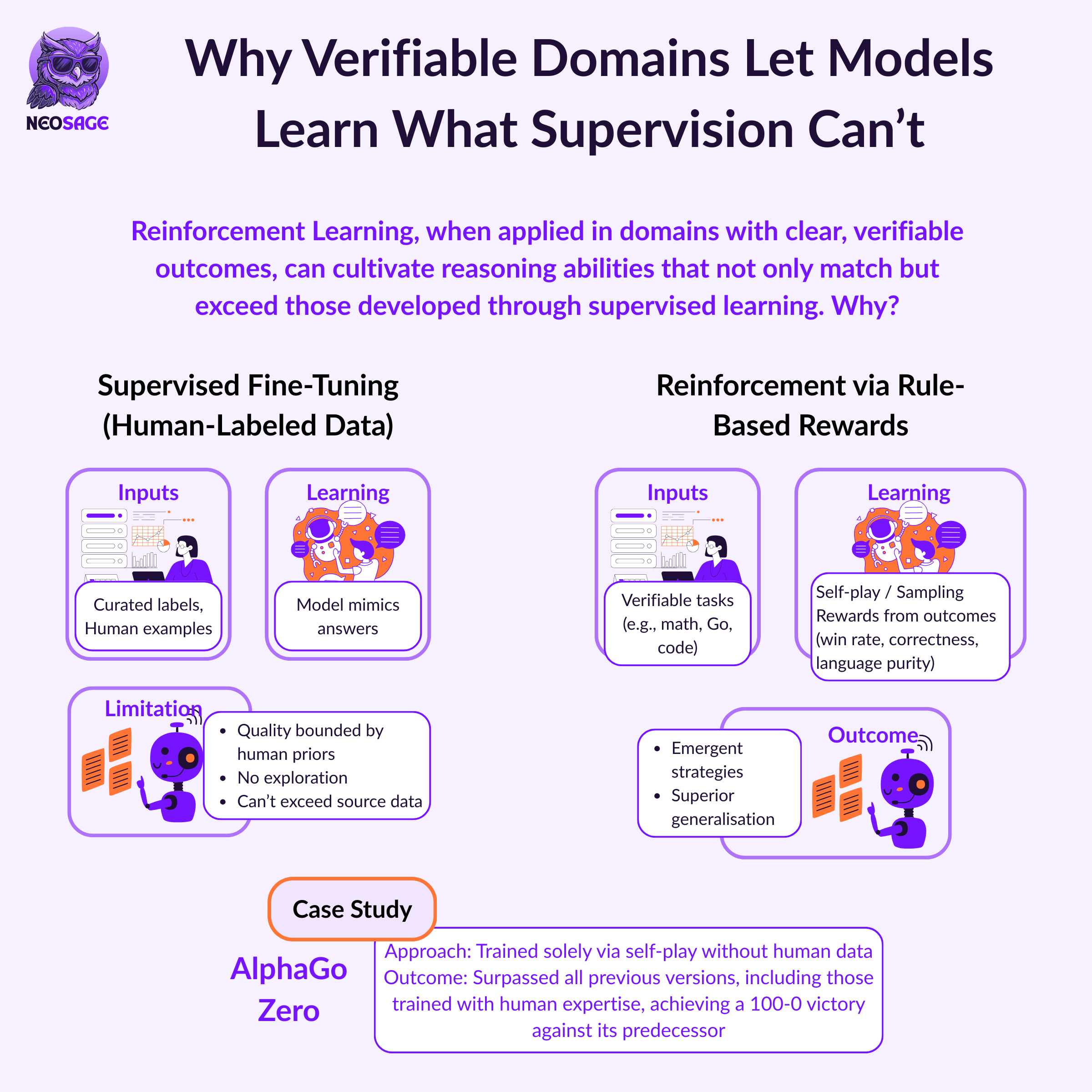
You can train reasoning without examples, but only if you can score it.
R1-Zero proved this. The constraint wasn’t data — it was verifiability. Reward mattered more than supervision.
You can't reinforce cleanly until your outputs are readable.
Cold-start SFT wasn’t for alignment — it was to create a trainable structure. Format isn’t UX. It’s part of the loop.
Language consistency is a rewardable trait, not a hardcoded switch.
R1 didn’t block multilingual output. It made consistency the path to reward. That design generalises.
Distillation works only when the source system has the right behaviours.
No small model figured it out from scratch. The ones that worked copied output from a pipeline that already had reasoning baked in.
Strong models aren't trained once. They're debugged in passes.
Each stage in R1 fixed something broken by the last, without losing what worked. That’s the real blueprint.